| « Структуры данных и алгоритмы. Теория. Работа с массивами. Сортировки и поиск. | Структуры данных и алгоритмы. Теория. Рекурсия. » |
Структуры данных и алгоритмы. Теория. Усовершенствованные алгоритмы сортировки
Для усовершенствованных алгоритмов сортировки характерна зависимость скорости работы от количества элементов массива в виде логарифмической функции. Если внимательно рассмотреть график функции y=ln(x), то можно увидеть что на начальных этапах y растет очень быстро, а затем стабилизируется. Отсюда следует сделать вывод, что применение усовершенствованных алгоритмов сортировки имеет смысл для больших массивов элементов, на небольших последовательностях можно добиться лучшего результата применяя простейшие алгоритмы (прямая вставка, шейкерная сортировка, метод простого выбора).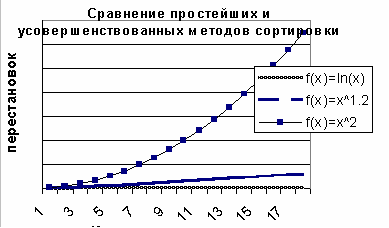
Основные усовершенствованные методы сортировки:
- Сортировка Шелла;
- Быстрая сортировка;
- Пирамидальная сортировка.
Сортировка Шелла
Сортировка Шелла представляет собой усовершенствованную модель сортировки методом простой вставки. В ее основе лежит следующее положение: в среднем при выполнении операции вставки каждый элемент перемещается на половину отрезка задающего отсортированную часть массива.
Таким образом, можно улучшить показатели сортировки, выполняя перемещения на большие расстояния, если классический алгоритм вставки делал перемещения элементов с шагом “1”, то сортировка Шелла выполняет целый ряд элементарных сортировок вставкой каждый раз с различной длиной шага. Так в первый проход сортируются элементы отстоящие друг от друга на 4 позиции, потом на 2 позиции, и наконец выполняется контрольная сортировка с шагом 1. Следует учитывать, что при каждом шаге сортировки выполняется относительно малое количество перестановок, а когда дело доходит до последнего прохода (идентичного методу простой вставки), то массив практически упорядочен.
Шаги, используемые в данном алгоритме способны варьироваться, однако существует требование того, чтобы числа образующие шаги (расстояния) не являлись множителями друг друга. В результате анализа выявляется, что зависимость времени выполнения от количества элементов носит вид y = x^1.2. Что, несомненно, является очень хорошим результатом для алгоритма в начале имевшего характеристику y = x^2. Следующим шагом мы рассмотрим алгоритм, действительно обладающий логарифмической кривой зависимости.
int arr[] = { 1, 3, 2, 7, 5, 8, 0, 4, 6, 9 , 10};
int steps [] = {9,5,3,1};
int STEPS_LENGTH = 4;
int ARR_LENGTH = sizeof (arr) / sizeof (int);
for (int k=0; k < STEPS_LENGTH; k++){
int h = steps [k];
for (int i=h; i < ARR_LENGTH;i++){
int elt = arr [i];
int j;
for (j=i-h; j >=0 && arr [j]>elt; j-=h )
arr [j+h] = arr [j];
arr [j+h] = elt;
}}printf ("Results\n");
for (int i = 0; i < ARR_LENGTH; i++)
printf ("%4d" , arr[i] );
Быстрая сортировка
Данный алгоритм является производным от алгоритма простой перестановки (пузырька), но при этом считается, что для повышения скорости работы необходимо выполнять перестановки элементов отстоящих друг от друга далеко. Так если у вас есть n элементов (которые расположены в порядке обратном желаемому), то выполнить их сортировку можно за n/2 шагов, так сначала необходимо выполнить перестановку первого и последнего элемента, потом меняются второй и предпоследний элементы и так далее. Итак, алгоритм быстрой сортировки заключается в том, что необходимо выбрать среди элементов массива некоторое значение m и расположить все элементы массива которые оказались больше чем m справа от него, а все меньшие соответственно слева. Затем данный процесс следует применить для правой и левой частей массива. Обычно данный процесс оформляется в виде рекурсивной процедуры, получающей в качестве параметров информацию об левой и правой границах сортируемого отрезка массива. Затем программа должна будет выбрать средний элемент m (в качестве такового наиболее выгодно использовать медиану отрезка, в качестве медианы понимают число, которое больше чем половина элементов массива, а также меньше чем другая его половина, так среди чисел 1,2,3,4,5 – в качестве медианы следует выбрать значение 3). Стоит отметить, что шанс выбрать медиану составляет 1/n, таким образом, в предположении о случайности массива следует брать центральный элемент, а не, например первый или последний. Что в случае упорядоченной последовательности приводит к ассиметричности результатов работы алгоритма. После преобразования получаются две новые последовательности одна, из которых имеет размер 1 элемент, а вторая n-1. В подобном случае быстрая сортировка вырождается в нечто способное называться поистине медленной сортировкой.
Примечание: наиболее просто алгоритм быстрой сортировки реализуется с использованием средств рекурсии. Если вы не уверены в собственных познаниях по этой теме, вам следует отложить изучение исходного кода примера, главное чтобы вы поняли концепцию данного приема. К рассмотрению метода quicksort следует вернуться самостоятельно после просмотра раздела “Рекурсия”.
void sort(int arr[], int L, int R) {
if (L >= R)
return;
int m = (L + R) / 2;
int mediana = arr[m];
int LL = L;
int RR = R;
while (LL < RR) {
while (arr[LL] < mediana)
LL++;
while (arr[RR] > mediana)
RR--;
if (LL <= RR) {
int swap = arr[LL];
arr[LL] = arr[RR];
arr[RR] = swap;
LL++;
RR--;
}}if (LL<R)
sort (arr , LL , R);
if (RR > L)
sort (arr , L , RR);
}// применение функцииvoid main(void) {
int arr[] = { 1, 3, 2, 7, 5, 8, 0, 4, 6, 9 };
int ARR_LENGTH = sizeof (arr) / sizeof (int);
sort (arr , 0 , ARR_LENGTH - 1);
printf ("Results:\n");
for (int i=0; i < ARR_LENGTH; i++)
printf ("%4d" , arr [i] );
}
Пирамидальная сортировка
Данный вид сортировки является дальнейшим развитием алгоритма сортировки прямым выбором.
Напомню, что в данном алгоритме итеративно решалась задача поиска самого маленького элемента (предположим, что стояла задача сортировки по возрастанию) в массиве с его установкой на первую позицию, затем данный процесс повторялся для остатка хвоста массива (2..n) элементы, затем (3..n), до тех пор, пока весь массив не был упорядочен. Действительно если рассмотреть количество шагов просмотра массива то можно увидеть, что на первом шаге необходимо было просмотреть n-1 элементов, на втором n-2 и так далее до 1, если воспользоваться свойством арифметической прогрессии то можно получить, что суммарное количество просмотров порядка (n^2-n)/2.
Однако следует заметить, что после первого прохода по массиву в поиске самого маленького элемента мы накопили некоторую информацию о соотношениях между собой остальных элементов, давайте подумаем, как ней воспользоваться. Если разбить исходный массив на пары элементов и сравнить элементы попарно между собой, то на это мы затратим “n/2” сравнения, дальше в каждой паре мы возьмем наименьшие элементы и сравним уже между собой, для этого нам потребуется “n/4” сравнения. Если мы продолжим так и далее, то за “n” сравнений мы найдем самый наименьший элемент и построим дерево элементов, для которого будет выполняться следующее соотношение.
- Элементы дерева пронумерованы от 1 до R.
- X(i) <= X(i*2) а также X(i) <= X(i*2+1).
Назовем такое дерево пирамидой. Теперь давайте мы заберем самый верхний элемент данной пирамиды (данный элемент будет самым маленьким в исходном массиве). А следующим шагом мы вычеркнем данный элемент из дерева так что получатся «дырки» и спускаясь с самого верха вниз согласно пути по которому “поднялся” верхний элемент каждую пустоту заменим на наименьший из нижележащих элементов. Таким образом, в самом внизу образуется дырка. А на верхнюю позицию будет помещен второй по малости элемент исходного массива. После того как мы “n” раз выполним данную операцию, наша пирамида будет пуста. Алгоритм пирамидальной сортировки создает представление пирамиды в виде “n” последовательно расположенных элементов. Реализует метод добавления к уже существующей пирамиде из элементов X(L+1),X(L+2), ..,X(R) нового элемента под номером L. А также реализует метод извлечения из пирамиды верхнего элемента и ее перестройку.
void shift(int * arr, int L, int R) {
int i = L, j = 2 * L + 1, elt = arr[L];
if (j < R && arr[j + 1] < arr[j])
j++;
while (j <= R && arr[j] < elt) {
arr[i] = arr[j];
i = j;
j = j * 2 + 1;
if (j < R && arr[j + 1] < arr[j])
j++;
}arr[i] = elt;
}void main(void) {
int arr[] = { 44, 55, 12, 42, 94, 18, 06, 67 , 8 , 121 , 64 , 56 , 75 };
int ARR_LENGTH = sizeof (arr) / sizeof (int);
int L = ARR_LENGTH / 2 + 1;
int R = ARR_LENGTH - 1;
while (L >= 1) {
L--;
shift(arr, L, R);
}while (R > 0) {
int tmp = arr[0];
arr[0] = arr[R];
arr[R] = tmp;
R--;
shift(arr, L, R);
}printf("Results:\n");
for (int i = 0; i < ARR_LENGTH; i++)
printf("%4d" , arr[i] );
}
Задания по разделу сортировки
- Отобразите порядок выполнения алгоритма сортировки методом выбора на следующей исходной последовательности (22, 15, 36, 44, 10, 3, 9, 13, 29, 26).
- Отобразите порядок выполнения алгоритма сортировки методом вставки для последовательности из предыдущего задания.
- Отобразите порядок сортировки для алгоритма пирамиды. Набор данных взять из задачи № 1.
- Отобразите порядок сортировки для быстрой сортировки. Набор данных взять из задачи № 1.
- Реализовать алгоритм сортировки слиянием на основании двух массивов упорядоченных в обратном порядке к требуемому.
- Продолжение предыдущей задачи. Отсортировать массив, разбивая его на группы 1,2,4,8 и так далее элементов. Разрешается использовать вспомогательный массив.
- Неупорядоченный массив отсортировать по убыванию, при этом необходимо избавиться от дублирующихся элементов.
- Решит задачу 6, но при этом в результирующем массиве не должно быть дублирующихся элементов.
- Путем слияния из возрастающего массива A и убывающего B получить массив C (отсортированный по возрастанию).
- Дана двумерная матрица A(n*m), необходимо каждую строку отсортировать по возрастанию, а затем строки упорядочить по убыванию.
- Дана двумерная матрица A(n*m), заполненная нулями и единицами, содержимое каждой строки следует рассматривать как двоичное представление числа. Необходимо отсортировать строки в соответствии с возрастанием этих двоичных чисел. Замечание: количество элементов строки более чем 32.
- Дан текстовый файл, каждая строка которого состоит из множества слов. Необходимо сформировать другой файл, содержащий строки исходного в порядке соответствующем количеству слов в строках.
- Дан текстовый файл, каждая строка которого состоит из множества слов. Первым словом идет дата события в формате D/M/Y, месяц записан римскими цифрами. Необходимо сформировать другой файл, содержащий строки исходного в порядке соответствующем порядку возрастания дат.
- Переставить строки и столбцы квадратной матрицы так, чтобы элементы на главной диагонали образовывали неубывающую последовательность.
- Задача о двух станках. Имеется N деталей, которые должны быть обработаны на двух станках в порядке первый, второй. На каждом станке может одновременно обрабатываться только одна деталь. Затратами на переналадку пренебречь. Известно время обработки каждой детали на станках, необходимо упорядочить детали так, чтобы затраты времени минимальны.
| « Структуры данных и алгоритмы. Теория. Работа с массивами. Сортировки и поиск. | Структуры данных и алгоритмы. Теория. Рекурсия. » |