Положить количество K = 0 ЦИКЛ Перебор всех элементов массива от 1 до КоличествоЭлементов(A) ЕСЛИ элемент A(i) = 0 ТОГДА K = K + 1 КОНЕЦ ЦИКЛА Вывод на экран K
| « Привет | Структуры данных и алгоритмы. Теория. Работа с массивами. Сортировки и поиск. » |
Структуры данных и алгоритмы. Теория. Введение
Введение. Классической формулой успеха для программиста является утверждение Н.Вирта «Хорошая программа – это единство продуманного алгоритма и эффективных структур данных». Данный учебный курс посвящен формированию научной системы мышления, умению проектировать алгоритмы и структуры данных. Перед изучением данного учебного курса предполагается, что студенты обладают знаниями в области простейших алгоритмов, владеют языком программирования высокого уровня, владеют основами объектно-ориентированного подхода в анализе и проектировании систем.Анализ алгоритмов
Понятия “алгоритма и структур данных” являются центральными в сфере компьютерных технологий, однако, чтобы называть некоторые структуры данных и алгоритмы «качественными и эффективными», следует использовать точные приемы их анализа. В качестве естественного критерия качества естественно выделить, во-первых, время исполнения. Также важным является объем затрачиваемых ресурсов памяти и дискового пространства. Внимание также следует уделить надежности и достоверности решений, их стабильности. Прежде всего давайте рассмотрим понятие затрат времени и того как его оценивать для произвольного алгоритма.
Время выполнения алгоритма или операции над структурой данных зависит, как правило, от целого ряда факторов. Простейший способ определить затраты времени на выполнение некоторого алгоритма это провести замеры времени до запуска и после завершения работы алгоритма.
#include <time.h>#include <stdlib.h>#include <stdio.h>void main (void){
time_t before = time (NULL);
for (int i=0; i < 10E8; i++)
(void)rand ();
printf ("time was taken about %d seconds" , time (NULL)- before);
}
time was taken about 17 secondsТак в выше приведенном примере идет генерация 10E8 случайных чисел и выводится затраченное время. Следует, однако, помнить, что подобный способ оценки времени не является точным, прежде всего, следует понимать, что в современных операционных системах параллельно выполняются несколько задач и выполнение нашего тестового примера может совместиться с иными видами активности. Далее следует понимать, что добиться устойчивой зависимости можно лишь при проведении многоразовых испытаний, иначе в причину влияния на конечный результат работы случайных факторов зависящих от специфики исходных данных, и других факторов, время выполнения алгоритма также будет случайной величиной. При проведении исследования необходимо запустить алгоритм с различным набором исходных данных, обычно сами данные генерируются случайным образом таким образом благодаря различающимся наборам данных будут отличаться также и затраты времени, классическим примером будет алгоритмы сортировки или алгоритмы поиска. После того как будет получен набор оценок, можно построить график и провести его аппроксимацию. Например, с помощью excel по исходным данным для графика можно построить линию тренда.
| x | y |
| 1 | 0,012753 |
| 10 | 46,3401 |
| 19 | 183,8774 |
| 28 | 259,4942 |
| 37 | 925,4948 |
| 46 | 17,15173 |
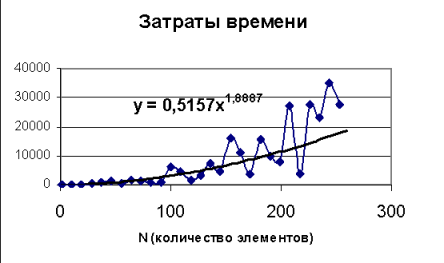
Подобный анализ всегда следует применять в случае использования не тривиальных алгоритмов, это подобно рекомендации заниматься разработкой приложения, использую для отладки не пробный набор из нескольких десятков записей или элементов, а реальные данные в полном объеме, что позволяет избежать модификации или даже полной переработки алгоритма или структур данных, если в последствии окажется их практическая не применимость. Имея набор результатов эксперимента можно провести интерполяцию и экстраполяцию и определить поведение алгоритма в реальных условиях.
В целом можно сказать, что время выполнения алгоритма или метода структуры данных возрастает по мере увеличения размера исходных данных, хотя оно зависит и от типа данных, даже при равном размере. Кроме того, время выполнения зависит от аппаратного обеспечения (процессора, тактовой частоты, размера памяти, места на диске и др.) и программ¬ного обеспечения (операционной среды, языка программирования, компилятора, интерпретатора и др.), с помощью которых осуществляется реализация, компиляция и выполнение алгоритма. Например, при всех прочих равных условиях время выполнения алгоритма для определенного ко¬личества исходных данных будет меньше при использовании более мощного компьютера или при записи алгоритма в виде программы на машин¬ном коде по сравнению с его исполнением виртуальной машиной, прово¬дящей интерпретацию в байт-коды.
Таким образом, мы приходим к выводу, что проведение анализа алгоритмов эмпирическим путем не является действительно надежным. Основные недостатки можно свести к следующим трем положениям:
1) эксперименты могут проводиться лишь с использованием ограниченного набора исходных данных; результаты, полученные с использованием другого набора, не учитываются.
В качестве демонстрации можно привести алгоритм подсчета суммы некоторого ряда с точностью до указанной дельта.

То алгоритм выдаст неправильное решение (равное конечному числу, хотя и очень большому) в виду того, что данный ряд является расходящимся и его суммой является бесконечность.
#include <math.h>#include <stdio.h>#include <conio.h>void main(void)
{double sum = 0 , ai;
int f = 1 , i = 1;
do{
sum+= (ai = 1.0/f);
f*=i++;
}while (fabs(ai) >= 1E-5);
printf ("exp = %lf" , sum);
(void) getch ();
}
3) для экспериментального изучения времени выполнения алгоритма необходимо провести его реализацию и выполнение.
Таким образом, мы приходим к необходимости использования для анализа алгоритмов методов общего анализа, который позволяет:
1) учитывает различные типы входных данных;
2) позволяет производить оценку относительной эффективности любых двух алгоритмов независимо от аппаратного и программного обеспечения;
3) может проводиться по описанию алгоритма без его непосредственной реализации или экспериментов.
Суть общего анализа заключается в том, что некоторому алгоритму ставится в соответствие функция F=F(n1, .., nm). В простейшем варианте это функция одной переменной n1 – количества исходных данных. Однако могут быть и другие переменные – например точность расчета или его достоверность. Так для определения того является ли некоторое число простым в случае больших чисел (длина двоичного представления более чем 200 бит) используют вероятностный метод, достоверность которого можно варьировать. Наиболее известные функции это линейные, степенные, логарифмические. Поэтому следует потратить время и вспомнить основы работы с ними.
При построении алгоритмов первая стадия идет с использованием не языка программирования, а описания на человеческом языке. Подобные описания не являются программами, но вместе с тем они более структурированы, чем обычный текст. В частности, «высокоуровневые» описания сочетают естественный язык и распространенные структуры языка программирования, что делает их доступными и вместе с тем информативными. Такие описания способствуют проведению высокоуровневого анализа структуры данных или алгоритма. Подобные описания принято называть псевдокодом. Следует также отметить, что для проведения анализа псевдокод является зачастую более полезным, чем код на конкретном языке программирования.
Пример псевдокода:
Название: Алгоритм подсчета количества элементов массива равных нулю.
Исходные данные: массив A
Требуется: количество элементов равных нулю
Начало алгоритма:
Для анализа алгоритмов и структур данных широко используют логарифмические и показательные (экспоненциальные) функции.
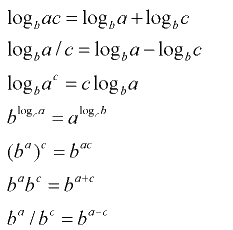
При анализе структур данных и алгоритмов зачастую используется понятие рада, которое можно определить следующим образом:
F(N) = A(1) + A(2) + … + A(N)Утверждение: если целое число N>=0 и действительно число 0 < a <> 1, то

Это пример геометрического ряда. Значение каждого элемента данного ряда увеличивается в геометрической прогрессии, если, конечно, a > 1. Таким образом, элементы данного ряда возрастают по экспоненте. Если вы вспомните начала нашего учебного курса и то, как вы работали с двоичной системой счисления, то также узнаете следующее равенство:
1 + 2 + 4 + .. + 2N-1 = 2 N - 1В случае арифметического ряда, в котором значение каждого элемента увеличивается на величину D = A(i) –A(i-1).

Ряды используются при анализе структур данных и алгоритмов, так как выполнение циклов естественно приводит к их возникновению. Например, одним из видов, часто возникающим при анализе структур данных и алгоритмов, является ряд геометрической прогрессии.
Простые приемы доказательства
Иногда возникает необходимость доказать некие утверждения в отношении к определенной структуре данных или алгоритму. Например, требуется продемонстрировать правильность и быстроту исполнения алгоритма. Для строгого доказательства утверждений необходимо использовать математический язык, который, послужит доказательством или обоснованием высказываний. К счастью, существует несколько простых способов по¬добного доказательства.
Прием «Пример»
Иногда утверждения записываются в обобщенной форме: «Множество S содержит элемент х, обладающий свойством V. Для доказательства данного утверждения достаточно привести пример х "принадлежит" S, который обладает данным свойством. В подобной обобщенной форме записываются, как правило, и маловероятные утверждения, например: «Каждый элемент х множества S обладает свойством Р». Чтобы доказать ошибочность данного утверждения, достаточно просто привести пример: х "принадлежит" S, который не обладает свойством Р. В данном случае элемент х будет выступать в качестве контр-примера.
ПРИМЕР: Профессор Амонгус утверждает, что любое число вида 2^n - 1 является простым, если n — целое число, большее 1. Утверждение профессора Амонгуса ошибочно.
ДОКАЗАТЕЛЬСТВО: чтобы доказать неправоту профессора Амонгуса, обходимо найти контр-пример. К счастью, для этого не потребуется много времени: 2^4 - 1 = 15 = 3 * 5. (Я надеюсь, вы помните, что простое число не имеет делителей отличных от 1 и самого себя).
Прием «Контратака»
Существует и другой способ, основанный на доказательстве от противного (использовании отрицания). Основными методами в данном случае являются контрапозиция и контрадикция. Использование методов противопоставления подобно зеркальному отражению: чтобы доказать, что «если X - истинно, то и Y — истинно», будем утверждать обратное «если Y — ложно, то и X — ложно». С точки зрения логики, данные утверждения идентичны, однако второе выражение, которое является котропозицией первого, более удобно.
ПРИМЕР: Если a*b — нечетное число, то а - нечетное или b – нечетное.
ДОКАЗАТЕЛЬСТВО: для доказательства данного утверждения рассмотрим контрапозицию: «Если а — четное число и b — нечетное, то a*b – четное. Пусть, а = 2*X, для некоторого целого числа X. Тогда a*b = 2*i*b, а следовательно произведение a*b — четное.
При использовании методов доказательства от противного полезным является использование законов логики.
. A + B = требуется выполнение A или B, или и A и B одновременно. . A * B = требуется одновременное выполнение A и B. . A – B = требуется выполнение A, но не B. . A xor B = требуется выполнение A, но не B или же B, но не A. (В повседневной жизни мы называем эту операцию ЛИБО). . ~A = отрицание A.В приведенном выше примере используется закон Де-Моргана, который в вышепринятых обозначениях будет записана так:
~(A*B) = ~A + ~B. ~(A+B) = ~A * ~B.При использовании метода контрадикции для доказательства того, что утверждение q — верно, вначале предполагается, что q — ложно, а затем показывается, что такое предположение приводит к противоречию (например, 2 * 2 <> 4). Придя к подобному противоречию, можно утверждать, что ситуации, при которой q - ложно, не существует, и, следовательно, q – истинно.
Индукция и инварианты цикла
В большинстве случаев в утверждениях о времени выполнения программы или используемом пространстве применяется целочисленный параметр n (обозначающий «размеры» задачи). Тогда когда мы формулируем утверждение X(n), то для множества значений n подобные утверждения равносильны. Так как данное утверждение относится к “бесконечному” множеству чисел, невозможно провести исчерпывающее прямое доказательство. В подобных ситуациях используют методы индукции.
Индукция
Метод индукции основан на том; что для любого n > 1. Существует конечная последовательность действий, которая начинается чего-то заведомо истинного и, в конечном итоге, приводит к доказательству того, что q(n) истинно. Таким образом, доказательство с помощью индукции начинается с утверждения, что q(n) истинно при n=1,2,3 и т.д. до некоторой константы k. Далее доказывается, что следующий «шаг» индукций q(n+1), q(n+2) также является истинным для n > k.
ПРИМЕР: Рассмотрим последовательность Фибоначчи.
F(1) = 1, F(2) = 2, F(n+2) = F(n-1) + F(n-2), где n >2.Докажем, что F(n) < 2n
Доказательство: доказательство истинности утверждения проведем с помощью метода индукции.
Исходные положения: (m <= 2). F(1) = l<2 = 21, F(2) = 2 <4 = 22.
Шаг индукции: (n>2). Предположим, что приведенное утверждение истинно для n' < n. Рассмотрим F(n). Так
F(n)= F(n - 1) + F(n - 2).Более того, так как n-1
F(n) < 2^(n-1) + 2^(n-2).Однако, 2^(n-1) + 2^(n-2) < 2^(n-1) + 2^(n-1) = 2^n. Что и требовалось доказать.
Нотация большого O.
При анализе алгоритмов, подсчете количества операций и времени их выполнения, не следует учитывать “мелкие детали”, следует пренебречь постоянными множителями и константами. На практике используют понятие функции большого O. предположим, что существуют две функции F(n) и G(n), считается, что F(n) <= O(G(n)) , т.е. функция O ограничивает сверху значения функции F. начиная с n=n0, сама же функция O(G(n)) часто записывается как C*G(n).
Например, алгоритм подсчета в массиве количества элементов равных нулю описывается O(n), где n – количество элементов.
ПРИМЕР:
1) 20n3+7,2n2-21,78n + 5 описывается как O(n3)
Обобщением примера будет являться тот факт, что всякий полином вида a(n)xn + a(n-1)xn-1 + a(n-2)xn-2 + a(0) описывается как O(xn).
2) 3*log(n) + log(log(n)) описывается как O(log(n)).
3) 2100 описывается как O(1)
4) 5/n описывается как O(1/n).
Обратите внимание на то, что функция O(n) ограничивает сверху целевую функцию затрат времени, но необходимо стремиться всегда выбирать такую функцию O(n), чтобы была максимальная точность.
Наиболее известные функции O в порядке их возрастания приводятся ниже:

Предостережения:
При использовании асимптотического анализа будьте внимательны, когда вы используете нотацию O, то часто пренебрегаете постоянными множителями и складываемыми константами. Однако в том случае если эта величина достаточно велика, например, в примере # 3: 2100 = O(1). Хотя вид функции O(1) более предпочтителен, чем алгоритм, описываемый функцией O(n), но практическое применение завоюет, разумеется, именно второй алгоритм.
Задания
1) Постройте графики функций 12n, 6n*log(n), n2, n3 и 2n, используя логарифмическую систему координат.
2) В алгоритме А выполняется 10n log (n) операций, а алгоритм В содержит n2 операций. Определите значение n0, при котором А лучше В, при n > n0
3) Выполните предыдущее задание, если алгоритм В выполняет n*sqrt(n) операций.
4) Докажите, что следующие два утверждения равнозначны:
• время выполнения алгоритма А есть O(F(n)); • в худшем случае время выполнения алгоритма А есть O(F(n)).5) Существует алгоритм find2D, который находит элемент х в массиве A размером n х n элементов (квадратная матрица). При каждой итерации алгоритм find2D просматривает строки массива А и вызывает алгоритм arrayFind фрагмент кода которого приводится ниже, до тех пор пока не будет найден элемент х или будут просмотрены все строки массива А. Каково худшее время выполнения алгоритма find2D, выраженное с помощью переменной n. Является ли время выполнения алгоритма линейной функцией? Почему?
Алгоритм arrayFind в виде псевдокода:
Входные данные: элемент X и массив A содержащий N элементов.
Требуется: Индекс “i” элемента массива A(i) = X или же, если такого элемента нет, то -1.
НАЧАЛО АЛГОРИТМА Положим I = 0 ЦИКЛ ПОКА I < n ВЫПОЛНЯТЬ ЕСЛИ X == A (i) ТОГДА ВЕРНУТЬ i I = I + 1 КОНЕЦ ЦИКЛА ВЕРНУТЬ –1 КОНЕЦ
| « Привет | Структуры данных и алгоритмы. Теория. Работа с массивами. Сортировки и поиск. » |