| « Структуры данных и алгоритмы. Теория. Рекурсия. | Структуры данных и алгоритмы. Теория. Общие правила и рекомендации к разработке собственных контейнерных структур данных » |
Структуры данных и алгоритмы. Теория. Динамические структуры данных
Мы уже знакомы с такими типами данных как скалярные типы (целые, вещественные числа, логические величины), массивы, записи (структуры). У всех этих типов есть общая черта – когда мы создаем переменную заданного типа, мы жестко ограничиваем ее структуру и набор допустимых значений. Так объявив массив размерностью 10 элементов в большинстве языков программирования не возможно увеличить или уменьшить его размер. В таком случае мы говорим, что тип определяется на этапе разработки программы или является статическим. В противоположность статическим типам существуют динамические типы данных. Для них характерно изменение на этапе выполнения не только отдельных значений, которые они принимают, но и структуры. Динамические типы данных наиболее часто являются по своей природе рекурсивными, т.е. динамический тип данных «X» состоит из набора компонент, некоторые из которых имеют тип «X». Вспомните, что с помощью рекурсии мы могли описать конечным набором выражений бесконечное множество объектов. Так в математике определение натурального числа основывается на положении:- 0 – есть натуральное число;
- всякое число, следующее за натуральным является натуральным.
При построении рекурсивных алгоритмов, важное значение имело понятие терминальной ветви вычисления. Также и для рекурсивных типов данных необходим инструмент, который ограничивал их размер. В качестве простейших примеров, когда является необходимым использовать динамические типы данных можно привести задачу создания класса DynamicVector, который будет служить для хранения некоторого множества чисел. Вы уже обладаете необходимыми знаниями, для того чтобы написать следующий фрагмент кода:
class DynamicVector {
protected:
int * data;
int count;
public:
DynamicVector (int s) : data (new int [s] ) , count (s) {}
~DynamicVector () {delete [] data;}
int & operator [] (int idx) {
assert (idx >=0 && idx < count);
return data [idx];
}};
Еще одним примером необходимости использования динамических структур данных будет задача анализа математических выражений (для упрощения будем рассматривать только бинарные операции). Действительно любое математическое выражение может быть представлено как “X op Y”, где X,Y – это скаляры или математические выражения, а “op” – операция над ними. Общепринято при повторяющихся вычислениях по формуле с изменениями значения переменных входящих в нее, для оптимизации по скорости выполнять только один раз анализ строки и затем размещать полученное выражение в некоторой специализированной структуре данных.
Другой пример необходимости использования рекурсивных типов данных это представление генеалогического дерева. В действительности генеалогическое дерево содержит информацию о некотором лице “X” а также его родителях, информация о которых представляется также в виде генеалогического дерева. Обратите внимание, в этой формулировке я употребил слово “также” – мы видим самоподобие структур данных – их рекурсивность, а рекурсивные структуры данных и динамические – это почти синонимы.
Итак, как я сказал ранее, структура динамического типа данных не фиксирована и определяется на этапе выполнения программы, следовательно, не возможно заранее выделить для хранения переменной фиксированного участка памяти. Выделение памяти должно проходить на этапе выполнения программы. Все языки программирования имеют средства для выполнения операции выделения и освобождения не нужной памяти.
| Язык | Выделение памяти | Освобождение памяти | Обозначение пустой ссылки |
| Pascal | New | Dispose | NIL |
| C | Malloc | Free | NULL |
| C++ | New | Delete | NULL |
| Java | New | Автоматически | null |
void main (void){
int arr [1000000];
}
void main (void){
int * arr = new int [1000000];
// some code … некоторые действия с данным большим массивомdelete [] arr;
}
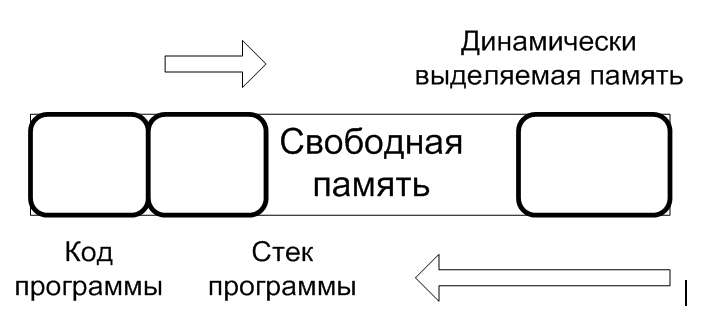
Динамические структуры данных наиболее часто применяются для создания контейнеров – специальных типов данных для хранения определенного множества элементов, а также реализующих определенную дисциплину обслуживания (добавления, удаления, поиска, изменения) хранимых элементов.
Списки
Наиболее простым типом контейнера является список. Так, как количество элементов списка заранее не известно, то список определяется по следующему рекурсивному правилу:
- NULL – список (пустой список);
- A = (x, B) – список, в данном случае “x” – элемент списка, “B” – список.
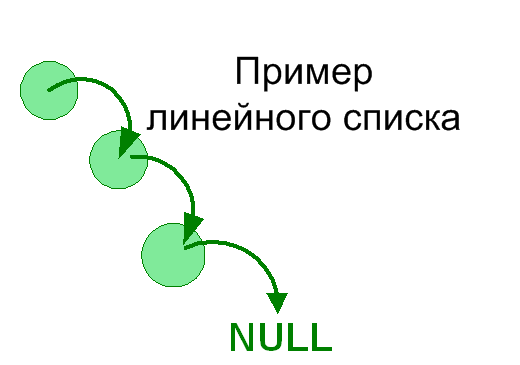
Рассмотрим пример объявления узла списка и заполнения его элементами 1..n.
struct LNode {
int inf;
LNode * next;
};
Схема наполнения элементами списка приводится ниже.
LNode *begin = NULL
for (int i=0; i < 100; i++){
LNode *n = new LNode;
n->inf = i;
n->next = begin;
begin = n;
}
last->next = n;
n->next = NULL;
n->inf = i;
Node * last = NULL;
Node * first = NULL; // ссылка на начало нашего списка
// некоторый объем кода в котором last начинает ссылаться не некоторый//элемент – последний в нашем спискеlast->next = n;
n->next = NULL;
n->inf = i;
last = n;
void addElement (int inf , LNode ** begin){
LNode * n = new LNode;
n->inf = inf;
n->next = *begin;
*begin = n;
}// добавлениеLNode *begin = NULL;
for (int i=0; i < 100; i++)
addElement (i , &begin);
- если список пуст, то ничего не надо делать (конец работы алгоритма);
- если список не пуст, то сначала необходимо будет распечатать первый элемент, а затем остаток списка (так же являющийся списком).
Очевидно, что данный алгоритм также может быть легко представлен в виде простейшей итерации.
LNode *p = begin;
while (p){
printf ("%5d" ,p->inf);
p =p->next;
}
LNode *p = begin;
while (p){
LNode *temp = p->next;
delete p;
p = temp;
}
void insertElementAfterCurrent (LNode **cur , int inf){
LNode * n = new LNode;
n->inf = inf;
n->next = (*cur)->next;
(*cur)->next = n;
}
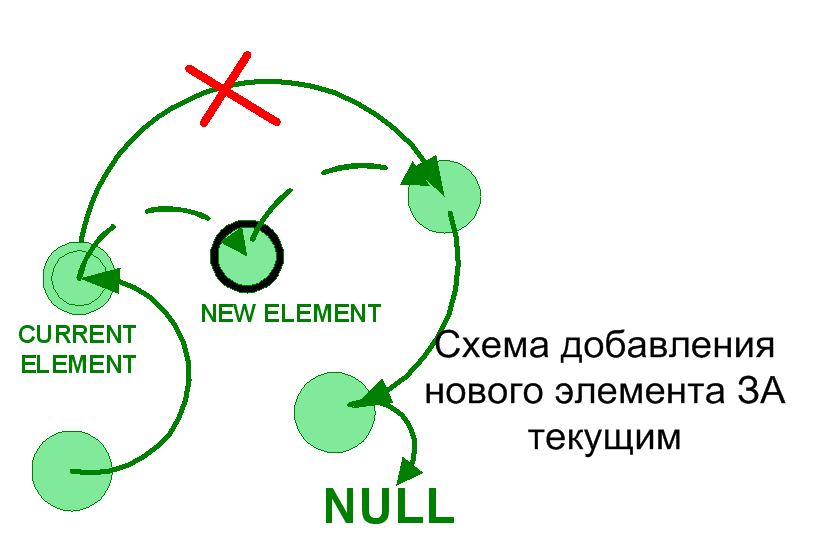
Операция вставки элемента до текущего не столь проста. Необходимо найти элемент, который ссылается на текущий.
Ниже приводятся два способа решения этой задачи:
void insertElementBeforeCurrent (LNode **begin , int inf , LNode *cur){
LNode *n = new LNode;
n->inf = inf;
n->next = cur;
LNode * p = *begin;
while (p && p->next != cur)
p=p->next;
if (cur == *begin){ // элемент перед которым необходимо сделать вставку это первый элемент
*begin = n;
}elseif (!p) {
perror ("Error: element cannot be found");
abort ();
}elsep->next = n;
}// схема использования функцииinsertElementBeforeCurrent (&begin , -2 , begin);
insertElementBeforeCurrent (&begin , -3 , new LNode);
void psevdoInsertElementBeforeCurrent (LNode *cur , int inf){
LNode * n = new LNode ;
n->inf = cur->inf;
cur->inf = inf;
n->next = cur->next;
cur->next = n;
}
void AnotherWayInsertElementBeforeCurrent (LNode **cur , int inf){
LNode * n = new LNode ;
n->inf = inf;
n->next = *cur;
*cur = n;
}
LNode *begin = NULL;
for (int i=0; i < 10; i++){
LNode *n = new LNode;
n->inf = i;
n->next = begin;
begin = n;
}LNode *b = begin;
insertElementBeforeCurrent (&begin , -33 , begin);
LNode *p = b;
while (p){
printf ("%5d" ,p->inf);
LNode *temp = p->next;
delete p;
p = temp;
}
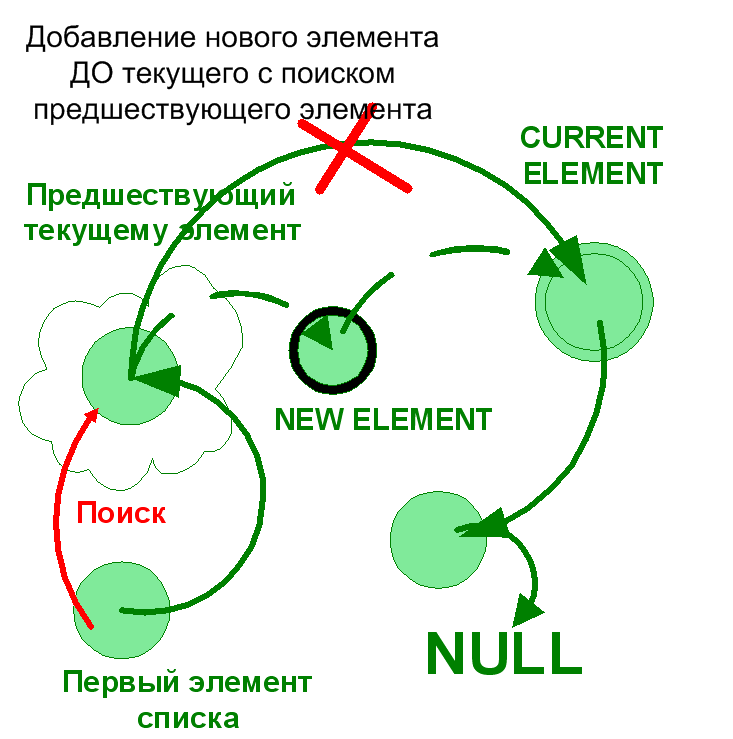
Далее рассмотрим операцию удаления элементов списка. Также как и при добавлении элементов существуют отличия в реализации в зависимости от того, как будет выполняться удаление: до или после текущего элемента или же удаляется сам текущий элемент.
void deleteElementAfterCurrent (LNode *cur){
LNode * tmp = cur->next;
if (!tmp) // нет элемента для удаления
{perror ("Error: no element for remove");
abort ();
}cur->next = cur->next->next;
delete tmp;
}
void deleteCurrentElement (LNode **begin , LNode *cur){
if (*begin == cur){
LNode *n = *begin;
*begin = (*begin)->next;
delete n;
return;
}LNode * p = *begin;
while (p && p->next != cur)
p = p->next;
if (! p ){
perror ("Error: no element for remove");
abort ();
}deleteElementAfterCurrent (p);
}
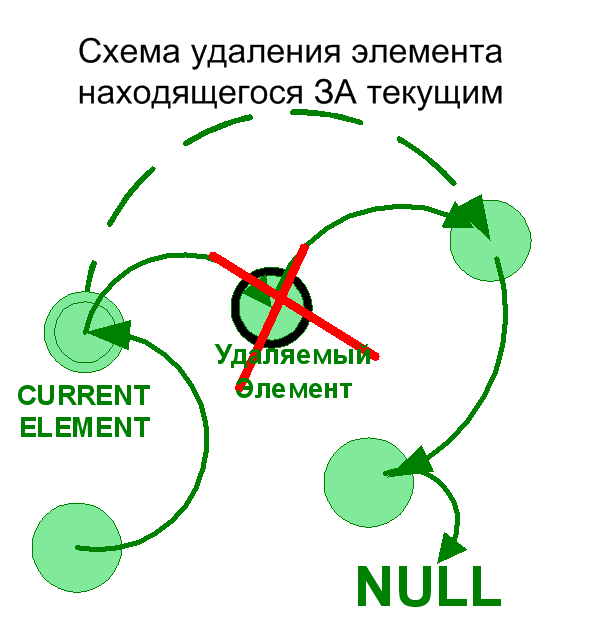
Линейные списки, с которыми мы работаем, являются родовым понятием для целого класса динамических структур данных.
Стек
Стек представляет собой линейный список с дисциплиной обслуживания LIFO (Last In First Out) или же FILO (First In Last Out). Это означает, что элемент, который был помещен в стек самым первым, будет извлечен из него самым последним. Для работы со стеком реализуют две функции, традиционно сложились их названия: pop – служит для извлечения элементов из списка, push – для добавления. Схему работы стека можно понять с помощью следующей таблицы:
| Операция | Состояние стека |
| Первоначальное состояние | (ПУСТО) |
| Push(A) | (A) |
| Push(B) | (BA) |
| Push(C) | (CBA) |
| POP = C | (BA) |
| POP = B | POP = B |
| Push(E) | (EA) |
#include <stdlib.h>#include <stdio.h>#define MAX_STACK_SIZE 100class PsevdoStack {
protected:
int size;
int arr [MAX_STACK_SIZE];
public:
PsevdoStack () : size (0){}
void push (int a){
if (size >= MAX_STACK_SIZE){
perror ("Stack Is Filled");
abort ();
}arr [size++] =a;
}int pop (){
if (size <= 0){
perror ("Stack Is Empty");
abort ();
}return arr[--size];
}bool isEmpty (){
return size == 0;
}};
void main (void){
PsevdoStack ps;for (int i=0; i < 10; i++)
ps.push (i);
while (! ps.isEmpty ())
printf ("%5d" , ps.pop ());
}
#include <stdlib.h>#include <stdio.h>struct StackNode {
int inf;
StackNode * next;
};
void push (StackNode ** root , int inf){
StackNode *n = new StackNode ;
n->inf = inf;
n->next = *root;
*root = n;
}int pop (StackNode ** root){
if (root == NULL){
perror ("Error: stack is empty");
abort ();
}int itmp = (*root)->inf;
StackNode * n = (*root)->next;
delete *root;
*root = n;
return itmp;
}void main (void){
StackNode * root = NULL;
for (int i=0; i < 10; i++)
push (&root , i);
while (root)
printf ("%5d" , pop(&root));
}
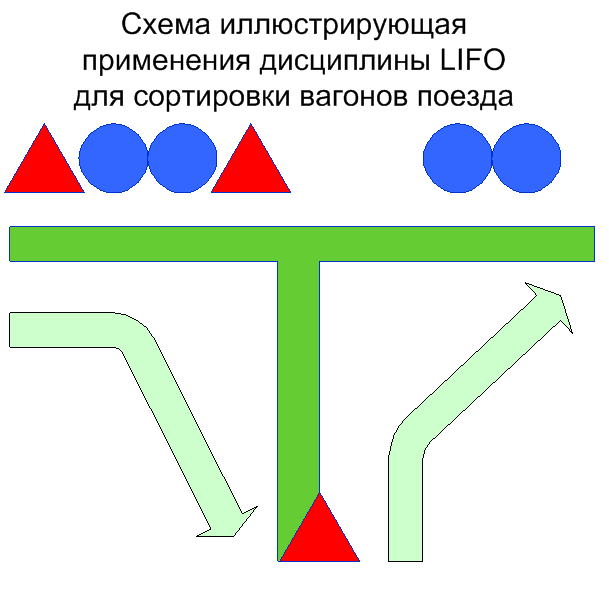
Пример: Еще одним примером стека кроме железнодорожного тупика можно назвать метод, применяемый в браузерах для хранения истории посещения страничек в сети интернет: когда пользователь вводит новый адрес, он помещается в стек. Таким образом, при нажатии на кнопку “НАЗАД” последний положенный элемент извлекается и пользователь возвращается на предшествовавшую текущей страницу.
При создании стека, который будет интенсивно использоваться: т.е. будет большое количество операций добавления и удаления элементов, что приводит к фрагментации памяти и большим накладным расходам на выделение и освобождение ресурсов, то имеет смысл создать пул памяти который будет выделяться в начале работы программы (и возможно будет расти по мере необходимости) и именно внутри этого пула будут размещаться элементы стека. Пример кода реализующий данную функциональность приводится ниже:
#include <iostream>#include <assert.h>template <class T>
class MySuperStack {
T * heap;
int s;
int a;
int p;
public:
MySuperStack (int s1, int a1) :
heap( (T *) malloc (s1*sizeof(T)) ), s(s1), a(a1), p(0) {}
void push(T tt);
T pop(void);
~MySuperStack() {
free(heap);
printf ("\nMemory was Free\n");
}};
template <class T> void MySuperStack<T>::push (T tt){
if(p==s){
s+=a;
heap=(T*)realloc(heap,s*sizeof(T));
}heap[p++]=tt;
}template <class T> T MySuperStack<T>::pop (void){
if ( p <= 0)
exit (0);
return heap[--p];
}void main (void){
MySuperStack ms <int>(10 , 10);
ms.push (123);
ms.pop ();
}
Задание: В большинстве языков программирования символы скобок “[({})]” должны быть симметричными. Составить алгоритм, который проверяет корректность заключения в скобки некоторой строки символов за время пропорциональное размеру строки. В качестве вспомогательной структуры данных использовать стек.
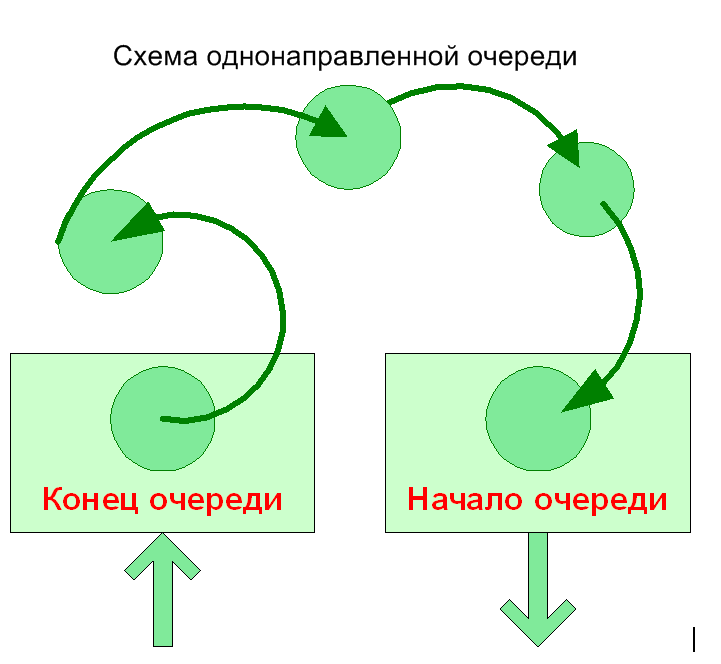
Очередь
Следующей структурой данных, которую мы рассмотрим, будет очередь. Она подобна стеку за исключением того, что работает по принципу FIFO (First In First Out). Таким образом, для очереди характерно добавление элементов в конец, а удаление из начала. Заметьте, что именно в таком порядке и никак иначе. Для очереди равно как и для стека характерно отсутствие механизмов доступа к произвольному элементу последовательности. Доступ к первому элемент автоматически означает и его удаление из очереди. Гораздо больший интерес представляет собой двунаправленная очередь или дек. Дек – характеризуется возможностью добавления и удаления элементов с обоих концов, для достижения данной функциональности необходимо ввести понятие двунаправленного списка. в тех списках с которыми мы работали ранее существовал только один элемент типа указатель на узел списка, который ссылался на следующий за ним элемент. В случае дека каждый элемент содержит в себе две ссылки на предыдущий и последующий элементы.
#include <stdlib.h>#include <stdio.h>struct DeqNode{
int inf;
DeqNode * next , * prev;
};
void addElementToEnd (DeqNode ** begin , DeqNode ** end , int inf){
DeqNode * n = new DeqNode ;
n->inf = inf;
if (*begin == NULL){
n->next = *end;
n->prev = *begin;
*end = *begin = n;
}else{
n->prev = *end;
n->prev->next = n;
(*end)->next = n;
n->next = NULL;
*end = n;
}}void addElementToBegin (DeqNode ** begin , DeqNode ** end , int inf){
DeqNode * n = new DeqNode ;
n->inf = inf;
if (*begin == NULL){
n->next = *end;
n->prev = *begin;
*end = *begin = n;
}else{
n->prev = NULL;
n->next = *begin;
n->next->prev = n;
*begin = n;
}}void removeElementFromEnd (DeqNode ** begin , DeqNode ** end ){
if (*begin == NULL){
perror ("error deq is empty, cannot delete last element");
abort ();
}if (*begin == *end){
delete *begin;
*begin = *end = NULL;
return;
}DeqNode *n = (*end)->prev;
delete *end;
n->next = NULL;
*end = n;
}void removeElementFromBegin (DeqNode ** begin , DeqNode ** end ){
if (*begin == NULL){
perror ("error deq is empty, cannot delete first element");
abort ();
}if (*begin == *end){
delete *begin;
*begin = *end = NULL;
return;
}DeqNode *n = (*begin)->next;
delete *begin;
n->prev = NULL;
*begin = n;
}void printForward (DeqNode ** begin , DeqNode ** end){
DeqNode * p = *begin;
while (p){
printf ("%5d" , p->inf );
p = p->next;
}}void deleteDeq (DeqNode ** begin , DeqNode ** end){
DeqNode * p = *begin;
while (p){
DeqNode *n = p->next;
delete p;
p = n;
}*end = *begin = NULL;
}void main (void){
DeqNode * begin = NULL, * end = NULL;
for (int i=0; i < 10; i++)
addElementToBegin (&begin , &end , i);
printForward (&begin , &end);
printf ("\n");
removeElementFromBegin (&begin , &end);
printForward (&begin , &end);
printf ("\n");
removeElementFromEnd (&begin , &end);
printForward (&begin , &end);
deleteDeq (&begin , &end);
}
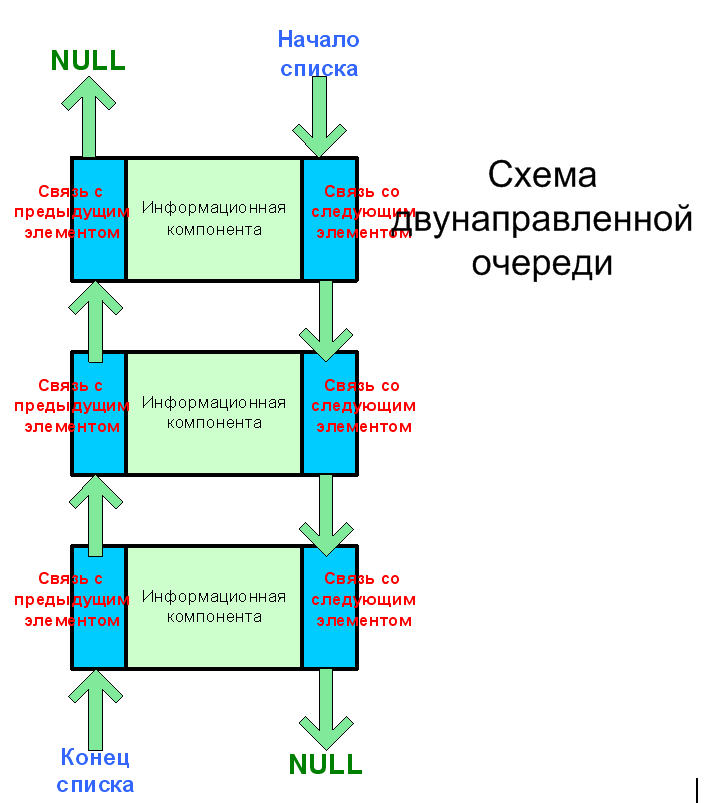
Следует отметить, что логически оба конца двусвязной очереди равноценны.
<h5> Задание: </h5>1) При продаже акций компании капитальная прибыль (или убыток) определяются разностью между стоимостью акций при продаже и той суммой, которая была уплачена при их покупке. Этот механизм понятен при операциях с одной акцией, однако при большом количестве акций, которые продавались и покупались в течении длительного времени, необходимо установить какие именно акции продаются. Стандартный бухгалтерский принцип определения продаваемых акций – заключается в использовании метода FIFO: продаваемые акции – это те, которыми владеют наиболее долгое время. Допустим, покупаются 100 акций по цене 20$ за акцию в первый день, затем 20 акций по 24$, 200 акций по 36$ и наконец в четвертый день продаем 150 акций по 30$. В данном примере согласно принципу FIFO 100 акций были теми которые мы купили в первый день, 20 – во второй, и 30 – в третий. Тогда капитальная прибыль составит 100*10 + 20*6 + (-6)*30 = 940$.
Необходимо написать программу исходными данными, которой будет являться последовательность банковских операций:
- купить X акций по цене Z$;
- продать X акций по цене Z$.
Дни операций идут по порядку, количество акций – целое. Необходимо определить итоговую прибыль или убыток.
3) Создайте реализацию однонаправленной очереди в виде класса, внутренний механизм которого использует предварительно выделенный объем памяти массива для хранения элементов очереди.
4) Развейте вышеприведенный пример добавив возможность роста очереди по мере необходимости. Подсказка: воспользуйтесь решением из примера стека.
5) Создайте реализацию кругового списка в виде класса с предварительно выделяемой памятью.
6) Создайте рекурсивный алгоритм подсчета количества узлов списка.
7) Создайте рекурсивный алгоритм умножения двух больших чисел, заданных в виде набора цифр хранимых с помощью очереди.
| « Структуры данных и алгоритмы. Теория. Рекурсия. | Структуры данных и алгоритмы. Теория. Общие правила и рекомендации к разработке собственных контейнерных структур данных » |