| « Структуры данных и алгоритмы. Теория. Классические задачи программирования | Структуры данных и алгоритмы. Теория. Рекуррентные уравнения. Динамическое программирование. » |
Структуры данных и алгоритмы. Теория. Порождение и перебор комбинаторных объектов
Во многих прикладных задачах требуется найти оптимальное решение среди очень большого числа вариантов, важно чтобы их количество было конечным или, в крайнем случае, генерируемая последовательность должна иметь монотонный характер для упрощения задачи поиска экстремума целевой функции в его окрестностях. В общем случае переборный алгоритм состоит в генерации всех возможных вариантов и сравнении их между собой в поиске наилучшего. Комбинаторика – раздел математики, в котором изучаются вопросы о том, сколько и каких комбинаций подчиненных определенным законам можно составить из выделенных объектов. В теории комбинаторики выделяют следующие виды комбинаторных объектов:- последовательности;
- перестановки;
- множество подмножеств заданного множества и т.д.
Схема перебора всегда будет одинакова:
- во-первых, надо установить ПОРЯДОК на элементах, подлежащих перечислению (в частности, определить, какой из них будет первым, а какой последним);
- во-вторых, научиться переходить от произвольного элемента к непосредственно следующему за ним, данное требование очень важно, т.к. возвращаться к пропущенным в процессе перебора элементам будет сложнее, чем задать алгоритм сплошного перебора.
Наиболее естественным способом упорядочения составных объектов является лексикографический порядок, принятый в любом словаре (сначала сравниваются первые буквы слов, потом вторые и т.д.) - именно его мы и будем чаще всего использовать. А вот процедуру получения следующего элемента придется каждый раз изобретать заново. Пока запишем схему перебора в таком виде:
- X = First
- Пока X != Last
- X = Next (X)
- Конец
А теперь мы рассмотрим конкретные алгоритмы генерации последовательностей.
Перестановки
Перестановка – это комбинация элементов из N разных элементов взятых в определенном порядке. Необходимо отметить, что в перестановках порядок следования элементов важен и в перестановке должны быть задействованы все N элементов.
Например: для последовательности A,B,C существуют следующие перестановки: <strong>a,b,c; a,c,b; b,a,c; b,c,a; c,a,b, c,b,a</strong>;Количество перестановок для N элементов порядка N!. Действительно: на первое место может быть помещен любой из N элементов (всего вариантов N), на вторую позицию (N-1) элементов, итого вариантов N*(N-1), и если продолжить данную последовательность для всех мест, то получим: N*(N-1)*(N-2)* ... *1;
Рассмотрим задачу получения всех перестановок чисел 1..N (то есть последовательности длины N, в которые каждое из чисел 1..N входит ровно по одному разу). Существует много алгоритмов генерации перестановок, которые отличаются порядком получаемых перестановок. Наиболее известна лексикографическая перестановка.
Это значит, что перестановки сравниваются слева направо, поэлементно и большей из них является та, в которой встретился элемент, который больше за соответствующий ему элемент в другой перестановке.
Пример: S=(3,5,4,6,7) L=(3,5,6,4,7). S<L, т.к. S3 < L3.Рассмотрим пример генерации перестановок: предположим, что необходимо получить все перестановки чисел 1,2,3,4,5. первой перестановкой будет (1,2,3,4,5), а последней (5,4,3,2,1). Предположим, что на некотором шаге работы была получена перестановка P = (3,4,5,2,1) = (p1, p2, p3,p4, p5).
Для получения перестановки следующей за ней необходимо выполнить следующие шаги:
- Необходимо просмотреть перестановку S справа налево и при этом следить за тем, чтобы каждый следующий элемент перестановки (элемент массива с большим номером) был не более чем предыдущий (элемент массива с меньшим номером). Как только данное соотношение будет нарушено необходимо остановиться. В нашем примере это элемент p2 .
- Снова просмотрим пройденный путь (справа налево) пока не дойдем до первого числа, которое больше чем отмеченное нами p2, это p3.
- Необходимо поменять местами элементы p2 и p3.
- Теперь в части массива, которая размещена справа от позиции p3 (после перемещения) надо отсортировать все числа в порядке возрастания. Благодаря тому, что до этого они все были уже записаны в порядке убывания необходимо данную подпоследовательность просто перевернуть. Таким образом мы получим новую последовательность S=(3,5,1,2,4). Которая будет рассматриваться при генерации следующей перестановки.
Замечание: на практике при генерации перестановок никогда не выполняют обмены непосредственно информационных элементов. Например, если у нас есть класс, описывающий студента - “Student” и нам необходимо получить перестановки студентов группы, то принято создать массив с порядковыми номерами студентов и выполнять перестановки именно на этом массиве, а по порядковому номеру обращаться к соответствующему объекту студента.
Задание: получить перестановку лексикографически следующую за (5,4,6,2,1,3).
Пример исходного кода алгоритма генерации всех перестановок в лексикографическом порядке.
#include "stdio.h"#include <algorithm>using namespace std;
const N = 6;
void main (void){
int arr [N] , i , count = 1;
for (i=0; i < N; i++)
arr [i] = i + 1;
do{
for (i=0; i < N; i++)
printf ("%d" , arr [i]);
printf ("\n");
for (int j = N - 2 ; j >= 0 && arr [j+1] < arr [j]; j--) ;
int k = j;
if (k == -1) break;
for (j = N - 1 ; j >= 0 && arr [j] < arr[k]; j--) ;
int k2 = j;
swap ( arr [k] , arr [k2]);
reverse (&arr [k+1] , &arr [N]);
count++;
}while (true);
printf ("count of all combinations = %d\n" , count);
}
#include "string.h"#include "stdio.h"#include <algorithm>#include <vector>#include <stack>using namespace std;
const N = 5;
int glob_c ;
void roll (int * arr , int n , int p){
if (n == p){
for (int i = 0; i < N; i++)
printf ("%d" , arr [i]);
printf ("\n");
glob_c++;
}else{
for (int i = 0; i < n-p; i++){
rotate (arr + p , arr + p + 1 , arr + N);
roll (arr , n , p +1);
rotate (arr + p , arr + p - 1 , arr + N);
}}}void main (void){
int arr [N];
printf ("----- start ----\n");
int i;
for (i = 0; i < N; i++)
arr [i] = i+1;
roll (arr , N , 0);
printf ("glob_c=%d" , glob_c);
}
Сочетания
Сочетания представляют собой наборы элементов, которые отличаются хотя бы одним элементом, и каждый из которых (каждый набор) содержит всегда M элементов, взятых из разных N элементов. Важно, что в сочетаниях порядок следования элементов не учитывается.
Пример : из элементов S=(a,b,c), можно получить следующие сочетания по два: C1 = a,b; C2=b,c; C3=a,c;
Количество сочетаний из N элементов по M обозначают С(N,M)=N!/(M!*(N-M)!) = C(N, N-M).
Упражнение: докажите правильность последнего равенства.
Рассмотрим алгоритм генерации сочетаний.
Раз порядок элементов в соединении не существенен, то получаемые выборки элементов будем упорядочивать в порядке возрастания. В качестве начальной конфигурации возьмем S=(1,2, .., M), т.е. B[j] = j, для j [1..M]. Сочетания будем получать в возрастающем лексикографическом порядке, т.е. последним сочетанием будет S=(N-M+1, N-M+2, .., N). Для каждого элемента последнего сочетания будет выполняться условие: B[i] = N-M+i. Для генерации очередного сочетания необходимо найти элемент B[i] с максимальным индексом j, таким чтобы выполнялось условие: B[i] < N-M+i.
Для этого просмотр элементов массива следует делать справа налево. Затем найденное значение B[i] увеличим на 1, а для всех K>j, положим значение B[K] = B [K-1] + 1. Если же такого B [i] не существует, то генерация сочетаний длины M завершена.
Задание: Какое сочетание будет сгенерировано вышеописанным алгоритмом следом за сочетанием (3,5,8), когда N =8, M=3.
#include "string.h"#include "stdio.h"#include <algorithm>#include <vector>#include <stack>using namespace std;
const N = 5;
const M = 3;
void main (void){
int arr [M];
printf ("----- start ----\n");
int i , j;
for (i = 0; i < M; i++)
arr [i] = i;
int cnt_c = 0;
do {
for (i = 0; i < M; i++)
printf ("%d" , arr [i]);
printf ("\n");
cnt_c++;
for ( j = M -1 ; j >=0 && arr [j] >= N - M + j; j--) ;
if ( j >= 0){
arr [j] ++;
for (i = j + 1; i < M; i++)
arr [i] = arr [i-1] + 1;
}else break;
}while (true);
printf ("cnt_c = %d" , cnt_c);
}
Размещения
Сочетания, которые отличаются друг от друга составом элементов или их порядком, каждое из которых состоит из M (M
Пример: для последовательности S=(a,b,c) по два будут являться следующие пары элементов: ab; ba; ac; ca; bc; cb.
Количество способов, которыми можно выбрать и разместить по M разным местам M из N различных объектов обозначают A(N,M)=N!/(N-M)!.
Упражнение: докажите данную формулу.
Пример: необходимо определить количество семизначных телефонных номеров, в которых не повторяется ни одна цифра. Данная задача на размещение по семи разным позициям 9 цифр от 0 до 9. Решением будет являться A(9,7).
Алгоритм генерации всех размещений основан на последовательном применении сначала алгоритма генерации всех сочетаний из N по M, а затем к каждой получившейся комбинации применения алгоритма генерации всех перестановок.
Задание: Действующий программный код генерации всех размещений разработать самостоятельно.
Генерация множества всех подмножеств заданного множества
Множеством называют группу объектов, выделенную по заданному признаку. Например, множеством является совокупность звезд на небе, студенты указанной группы, все деревянные стулья в аудитории. Подмножество – есть такое множество B, каждый элемент которого содержится в некотором другом множестве A (включающем или надмножестве). Например, множество звезд созвездия Скорпион является подмножеством звезд из всех созвездий Зодиака.
Множество, которое не содержит ни одного элемента, называется пустым. Пустое множество является подмножеством всякого другого множества.
Пример: множество всех натуральных чисел N "принадлежит" Z, является подмножеством всех целых чисел.
Для множества S = (a,b,c), множеством, содержащим всего его подмножества будет являться B=(() , (a) , (b) , (c) , (ab) , (bc) , (ac), (abc));
Количество всех подмножеств множества из N элементов порядка 2N.
Упражнение: докажите истинность данной формулы.
Для генерации всех подмножеств используется массив B [0..N], отметьте, что количество элементов массива на 1 больше чем необходимое, 0-ой элемент – фиктивный и используется для оптимизации алгоритма, и признака его завершения. Элементы массива будут принимать только два значения 1, 0 или TRUE, FALSE – соответственно, если элемент включается в выборку или не включается. Т.е. пустому множеству будет соответствовать массив со всеми нулями, а подмножеству, содержащему все элементы оригинального множества – массив в котором все элементы будут 1, или TRUE.
Если генерировать числа в диапазоне от 0 до 2N-1, и каждое из них переводить в двоичную систему счисления, то это представление совпадет с распределением нулей и единиц в массиве B. Будем считать это схемой 1.
Разумеется что задача перевода числа в двоичную систему требует затрат ресурсов, которых можно было бы избежать, поэтому мы будем моделировать операции сложения над числом в виде массива. Это схема # 2. При сложении массива с 1-ей мы будем просматривать массив B справа налево, заменяя единицы нулями до тех пор, пока не нейдем нуль, в который занесем единицу. Генерация подмножеств будет завершена, как только B [N] станет равным 1.
Далее приводится пример рекурсивного решения данной задачи. Разберитесь в нем.
void genCombinations (int * arr , int n , int curPos){
if (n == curPos){
printf ("\n-------------we have got next combination---------\n");
for (int i=0; i < n ; i++)
printf ("%d" , arr [i]);
}else{
arr [curPos] = 0;
genCombinations (arr , n , curPos+1);
arr [curPos] = 1;
genCombinations (arr , n , curPos+1);
}}void main (void){
int arrT [10];
genCombinations (arrT , 10 , 0);
}
Сочетания с повторениями
Размещения с повторениями
Размещения, которые мы рассматривали ранее, предполагали, что из N разных элементов в очередное соединение входил только один раз. Также выделяют размещения с повторениями, в таком виде размещений каждый из N элементов в очередное размещение по M элементов может входить несколько раз. Итак, размещением с повторениями называют такие размещения из N элементов по M, в которых один и тот же элемент может повторяться в каждом из размещений любое количество раз, но не более чем M раз.
Пример: для элементов a,b размещения с повторениями из 2 по 3 будут следующими:
aaa, aab, aba, abb, baa, bab, bba, bbb.Всего количество подобных размещений обозначается и будет составлять величину порядка:

Пример: Вася Тапкин положил в камеру хранения на вокзале свой багаж, и забыл код доступа, правда при этом он помнит, что в коде не было цифр 0,1,5. требуется найти сколько вариантов ему потребуется перебрать пока он не откроет свою ячейку? Здесь необходимо вычислить число размещений из (10-3) цифр на место 5-ти ключей, причем именно с повторениями. Следовательно, суммарное количество всех вариантов будет A = 7^5 = 16 807.
Для того чтобы создать алгоритм генерации списка всех размещений, вам сначала надо будет разобраться в том, почему именно такая формула (***) задает количество размещений. Если вы все еще помните начало учебного курса, когда вас знакомили с различными системами исчисления, то заметите, что если мы пронумеруем все элементы, участвующие в размещение номерами от 0 до N-1, по-порядку, то каждому из размещений можно поставить в соответствие некоторое число в N-ичной системе счисления, которое состоит из M цифр. Данное множество чисел будет принимать все значения от 00000 (итак все M нулей), до ((N-1)(N-1)…). Например, если вы посмотрите на первый пример с размещениями букв a, b, то, заменив букву “a” на ноль, а букву “b” на единицу, мы получим:
aaa, aab, aba, abb, baa, bab, bba, bbb. 000, 001, 010, 011, 100, 101, 110 , 111.Пример кода алгоритма, который генерирует все размещения с повторениями, приводится далее:
#include "stdio.h"const N = 3;
const M = 5;
void main (void){
int arr [M + 1];
for (int i=0; i <= M; i++)
arr [i] = 0;
int cnt_variants = 0;
while (!arr [0]){
for (i = M; i >= 1; i--)
printf ("%d" , arr [i]);
printf ("\n");
cnt_variants++;
arr [M] ++;
int j = M;
while (arr[j] == N){
arr [j] = 0;
arr [--j]++;
}}printf ("cnt_variants = %d\n" , cnt_variants);
}
Перестановки с повторениями
Перестановки из N элементов, в каждую из которых входят N1 одинаковых предметов одного типа, N2 одинаковых предметов другого типа и так далее, это требование выполняется для K различных групп предметов (очевидно, что N1+N2+ … + NK = N) называются перестановками из N элементов с повторениями:
Пример: перестановки из двух элементов a, b каждый из которых будет взят по два раза:
aabb, abab, abba, baab, baba, bbaa.Количество перестановок с повторениями может быть вычислено по следующей формуле:

Пример: в кондитерском магазине продаются четыре вида пирожных. Необходимо ответить на вопрос: сколькими способами можно купить 7 пирожных.
Это задача на подсчет количества сочетаний из N = 4 по M = 7. Согласно приведенной выше формуле: C = 10!/(7!3!) = 120.
Для того чтобы разобраться в непосредственно алгоритме генерации сочетаний следует внимательно прочитать доказательство корректности формулы (***).
Каждое сочетание с повторениями кодируют с помощью нулей и единиц: сначала записывается столько единичек сколько было взято элементов первого типа. Затем чтобы отделить элементы первого типа от элементов второго типа мы записываем один нолик. А затем – снова единицы – столько раз сколько у нас элементов второго типа. Потом снова ноль и так далее. Так для ранее приведенных сочетаний (**) мы получим следующие двоичные последовательности:
1110, 1101, 1011, 0111.Таким образом количество сочетаний с повторениями из N элементов по M будет равно количеству перестановок с повторениями, которые можно получить из M единиц и (N-1) нулей. Для того чтобы подсчитать эту величину применяется формула из предыдущей темы.
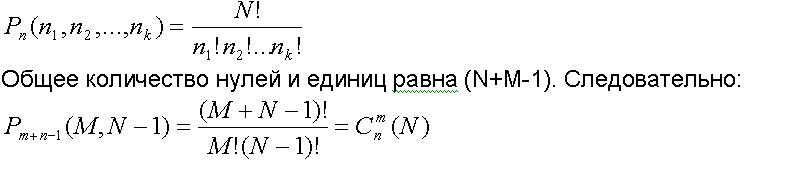
Оптимизация переборных задач
Часто встречаются задачи, в которых трудно найти решение отличное от полного перебора. Мы уже умеем выполнять типовые задачи перебора, однако следует помнить, что часто количество перебираемых вариантов слишком велико и подлежит оптимизации. В качестве примеров переборных задач можно привести: получить все четырехзначные числа, у которых все цифры нечетные. Так для решения данной задачи применяются алгоритм генерации всех размещений из пяти элементов (1,3,5,9) по 4.
К сожалению, дать конкретный алгоритм сокращения количества вариантов подлежащих перебору очень тяжело, т.к. в каждой ситуации следует находить свои зависимости.
Пример: двум медвежатам очень повезло: они в лесу нашли несколько кусков сыра и теперь хотят поделить их поровну. Т.е. каждому из них должен достаться одинаковый вес, может быть разным количеством кусков сыра. Например, если даны следующие куски сыра: 3, 7, 2, 5, 1 то их можно разделить, например, так: 7,2 и 3, 5, 1. Если же нам даны такие куски сыра: 1, 3, 7, 2 то их разделить не возможно. Предполагается, что вес каждого куска сыра является целым.
В качестве исходных данных для программы выступает количество кусков сыра N и множество их весов. В качестве выходного результата должен быть выведен способ деления этого сыра поровну, если конечно это возможно, в противной ситуации должно быть сообщение: «Раздел не возможен».
Первым шагом, разумеется, будет определение суммарного веса сыра “S” подлежащего разделу. В случае если это число будет нечетным, то раздел не возможен. Первое решение, которое приходит в голову всем начинающим программистам – это воспользоваться алгоритмом генерации всех подмножеств заданного множества, очевидно, что таким образом можно будет перебрать все возможные варианты раздела, каждый из которых необходимо оценить – равна ли сумма получившегося подмножества половине S. Однако данный алгоритм определяется O(2^N) – что является быстро растущей функцией и, следовательно, неприменим в ситуациях, когда количество кусков сыра велико. Для оптимизации количества переборов можно использовать следующие положения:
- очевидно, что нас не должны интересовать такие подмножества, в которых сумма элементов превосходит S/2. Таким образом, когда мы сгенерировали подмножество с весом S/2 все остальные множества, получающиеся из данного путем добавления к нему некоторых других элементов, нас не будут интересовать.
- Имеет смысл отдать самую большой кусок сыра одному из медвежат (в любом случае кто-то его должен получить), но благодаря этому мы уменьшим сумму, которую нам необходимо набрать из оставшихся элементов – следовательно, благодаря п.1 уменьшится также и количество перебираемых элементов. Следовательно, имеет смысл куски сыра отсортировать по величине.
- Если один из кусков сыра имеет вес равный половине искомой суммы S, то разбиение найдено.
- Если хотя бы один из кусков сыра имеет вес более чем S/2 то разбиение не возможно.
#include "string.h"#include "stdio.h"#include <algorithm>#include <functional>using namespace std;
const N = 20;
void main (void){
int arr [N];
int n;
int i , j;
printf ("n = ?");
scanf ("%d" , &n);
for (i = 0; i < n; i++){
printf ("arr [%d] = ?" , i);
scanf ("%d" , &arr [i]);
}int s = 0;
for (i = 0; i < n; i++)
s+= arr [i];
if (s % 2){
printf ("cannot divide s");
return;
}s/=2;
sort (arr , arr + n , greater<int>());
for (i = 0; i < n; i++)
printf ("arr[%d]=%d\n" ,i ,arr [i]);
printf ("\ns/2 = %d" , s);
int col_sel = 0;
int arr_sel [N];
arr_sel [0] ;
int cur_sum = 0;
int cur_position = 0;
do{
cur_sum += arr [cur_position];
if (cur_sum == s){
arr_sel [col_sel++] = arr [cur_position];
printf ("\n----combo found --- \n");
for (i = 0; i < col_sel; i++)
printf ("%d -- " , arr_sel [i]);
break;
}else{
if (cur_sum < s){
arr_sel [col_sel++] = arr [cur_position];
cur_position ++;
}else{
cur_sum -= arr [cur_position];
cur_position++;
}}}while (col_sel >= 0);
}
Задания к разделу "Основы комбинаторики"
- Сколькими способами можно раскрасить вершины куба в три цвета (например, красный, синий, зеленый). Вывести на печать все варианты.
- Сколькими способами можно надеть на нитку семь бусин двух цветов – белого и синего. Вывести на печать все возможные варианты.
- Сколькими способами можно раскрасить грани куба в четыре цвета. Напечатать все варианты.
- Дама собирается пригласить своих семерых друзей на несколько званных обедов. Каждый раз она решает приглашать только троих из всех семи гостей. Кроме того она хочет чтобы каждые из ее двоих гостей обязательно встретились за столом. Причем было бы неплохо если бы они встретились только один раз.
- Написать алгоритм выплаты заданной суммы денег всеми возможными способами. В наличии есть купюры стоимостью 1,2,5,10,20,100 рублей. Количество купюр каждого вида не ограничивается.
- Написать программу, которая из букв A,B,C строит слова длиной N, в котором два из любых подслов, которые стоят рядом различны. Например, слово – ABCABA – правильно, а слово CABABC – неправильное, т.к. сочетания букв AB стоят рядом.
- Существуют числа обладающие следующими особенностями: а) число делится на все свои цифры; б) число, полученное из исходного путем записи его цифр в обратном порядке также делится на все свои цифры. Примером такого числа будет 216, написать программу, которая печатать все трехзначные числа обладающие подобной особенностью. Числа с одинаковой первой и последней цифрой не учитывать.
- Составить алфавит племени Тумба-Юмба, если известно, что:
- Алфавит языка состоит из четырех букв: a,b,c,d.
- Слова на этом языке не имеют двух или более одинаковых букв подряд.
- Клетчатое поле размером N*N охраняется M воинами царя Артаксеркса, которые занимают разные клетки этого поля. Царь хочет разместить воинов так, чтобы обеспечить максимальную суммарную защиту границ своих владений (т.е. 4*(N+1) клеток, что находятся на границе поля). Каждый воин охраняет те соседние клетки, которые он видит по горизонтали, вертикали и диагонали. Защищенность клетки прямо пропорциональна количеству воинов, которые ее охраняют.
| « Структуры данных и алгоритмы. Теория. Классические задачи программирования | Структуры данных и алгоритмы. Теория. Рекуррентные уравнения. Динамическое программирование. » |