<http://family.site.com/#Vasya> <http://family.site.com/#hasFriend> <http://family.site.com/#Jim> . <http://family.site.com/#Jim> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://family.site.com/#Person> . <http://family.site.com/#Vasya> <http://family.site.com/#hasColor> <http://colors.site.com/red> . <http://family.site.com/#Vasya> <http://family.site.com/#birthDay> "2007.1.1" . <http://family.site.com/#Vasya> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://family.site.com/#Person> .
| « Семантическая сеть. Часть 1 | Семантическая сеть. Часть 3 » |
Семантическая сеть. Часть 2
Я продолжаю рассказ о Семантической Паутине и технологиях, которые, возможно, никогда не изменят будущего, если вы не окажите им немного помощи. Вкратце: основная идея семантической паутины - добавить к существующим веб-страницам немного информации ориентированной на машинную обработку, добавить сведения о самой информации и о том в каких отношениях она находится с другими страницами сети. Когда это случится, то по Сети будут путешествовать автономные Семантические Агенты, похожие на ИскИны, (Искусственные Интеллекты из популярных научно-фантастических рассказов). Они будут помогать искать информацию, планировать рабочий день, брать на себя все больше и больше рутинной работы.Почему я сказал “возможно, никогда не изменят будущего”? Если углубиться в историю, то сегодняшний Интернет – это самое простое решение, которое могло работать. Помимо Тим-Бернерса Ли над идеями Сети и гипертекста работали Дуглас Энгельбарт, Тед Нельсон (проекты memex, enquire, xanadu) и в своем оригинале выглядели они гораздо сложнее чем сегодняшний веб. “Самое простое решение“ было обусловлено не только техническими сложностями, но и тем фактором, что для роста сети необходимы генераторы наполнения. А что, если правила, по которым выполняется этот процесс, сложны (например, система Enquire каждой ссылке приписывала сведения о том, в каком взаимоотношении находятся связанные страницы, требовалось наличия двухсторонних ссылок)? Задумайтесь, кто будет заниматься генерацией информации, если это так сложно? Компьютерные энтузиасты, это само собой. Но если вы заядлый аквариумист и хотите рассказать про свои опыт выращивания золотых рыбок, то тратить несколько недель своей жизни на оформление документа по сложным правилам, налаживанием отношений с другими участниками создающими информацию, согласованию ссылок и терминов … Фактически, вы выполнили бы объем работы сравнимый с подготовкой книги для печати, но не получили бы за это ни копейки. А веб-страница, будучи построенной не по правилам, просто не открылась бы ни в одном из браузеров. В первоначальном виде семантическая сеть была бы полезна только ученым и никогда не смогла бы привлечь достаточное количество писателей и читателей и стала бы еще одной разновидностью библиотеки и довольно дорогой, кстати. Но что делать сейчас, когда техническая база достаточна как с точки зрения “железа” так и “умного софта”. Явно не ломать и не строить систему с нуля - нужно добавлять к существующей информации перед публикацией “кусочки семантики” (благо соответствующие стандарты приняты уже не первый год и есть конкретные программные продукты, понимающие эти стандарты). Объем капиталовложений в сеть растет с каждым днем, стоимость мирового рынка рекламы уже сравнима с годовым бюджетом нашей Республики, реклама становится все более контекстной, базы данных о пользователях социальных сетей все детальней и дороже, а сами пользователи становятся все более избирательными и “ленивыми”. Так что для того, чтобы остаться на “гребне волны” нужно не только добавлять к сайтам удобности и красивости (flash, видео, ajax), но и заняться упорядочением информации.
Возможно, что до того момента как ваши усилия превратятся в “поток золотых монет” пройдет еще несколько лет. Но когда это случится, то вы сможете продавать свою информацию более эффективно, чем те, кто не задумывался о семантике и должен переработать по новым правилам весь объем своих публикацией, чтобы надеяться на рейтинговые места в результатах выдачи поисковых машин или на “доступность” для тех самых мифических семантических агентов. Так что я призываю всех, кто занимается публикацией в сети информации добавить к ней семантику уже сейчас. На этой оптимистической ноте я перехожу к продолжению рассказа о формате RDF и его применении “здесь и сейчас”.
В прошлой статье я показал, как с помощью RDF можно описать некоторую сущность, указать на ее характеристики и отношения с другими сущностями (в качестве примера было выбрано описание некоторого человека по имени Вася). После того как я указал на такие простые характеристики как “дата рождения”, “цвет волос” и дал определения эти терминам с помощью ссылок на другие RDF-страницы, пора поработать с множественными характеристиками, например, списком друзей. Очевидно, что друзей у Васи очень много и нам нужен способ их группировки. Ведь не можем же мы начать создавать вложенные в Person элементы “friend_1”, “friend_2”, … это просто глупо. Для группировки некоторого количества связанных сущностей в RDF предусмотрен тег “
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="http://family.site.com/#"><ns:Person rdf:about="http://family.site.com/#Vasya" ><ns:hasFriend><rdf:Bag><rdf:li>Anna</rdf:li>
<rdf:li>Mary</rdf:li>
</rdf:Bag></ns:hasFriend></ns:Person></rdf:RDF>
<ns:Person rdf:about="http://family.site.com/#Vasya"><ns:hasFriend><rdf:Bag><ns:li><ns:Person rdf:about="http://family.site.com/#Mary" /></ns:li><ns:li><ns:Animal rdf:about="http://animals.site.com/#Murka" /></ns:li></rdf:Bag></ns:hasFriend></ns:Person>
В случае если список друзей Васи должен быть упорядочен по некоторому критерию, то вместо элемента “rds:Bag” нужно использовать тег “rdf:Seq”. И последний вид контейнера – выбор из списка альтернатив, например, список профессий на которые может учиться Вася:
<ns:Person rdf:about="http://family.site.com/#Vasya" ><ns:willStudy><rdf:Alt><ns:li><ns:Profession rdf:about="http://jobs.site.com/#Programmer" /></ns:li><ns:li><ns:Profession rdf:about="http://jobs.site.com/#Boss" /></ns:li></rdf:Alt></ns:willStudy></ns:Person>
<ns:willStudy rdf:parseType="Collection"><ns:Profession rdf:about="http://jobs.site.com/#Programmer" /><ns:Profession rdf:about="http://jobs.site.com/#Boss" /></ns:willStudy>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="http://family.site.com/#"><ns:Person rdf:about="http://family.site.com/#Vasya" ns:birthDay="2007.1.1"><ns:hasColor rdf:resource="http://colors.site.com/red"/><ns:hasFriend><ns:Person rdf:about="http://family.site.com/#Jim"/></ns:hasFriend></ns:Person></rdf:RDF>

Рядом с RDF находится технология RDFS (RDF Schema). Ее назначение – это описание данных с помощью некоторых классов и свойств этих классов. Понятие классов сходно с тем, что принято в мире объектно-ориентированного программирования: моделируемая область знаний представлена в виде множества объектов, каждый из которых строится на основании некоторого шаблона – класса. Так класс human определяется набором свойств ФИО, вес, дата рождения. Классы могут быть организованы в виде иерархии: класс “Кошка” является производным от класса “Животное”, и у каждого из этих классов есть свои специфические свойства. На основании классов создаются конкретные сущности (кошка Мурка). Важно понимать, что RDFS не является справочником всевозможных “готовых” классов и их свойств – это каркас для создания классов, именно, вами. Так что, мы изучаем еще синтаксис RDFS и затем можем сделать что-то практическое? Нет, еще нет: пирамида технологий более длинная. В основе всего лежит XML, на его основе построен RDF, на основе RDF создан RDFS. Но т.к. RDFS представляет только базовые элементы для построения онтологий, то был создан еще и язык OWL (Web Ontology Language). Но и это еще не все: ведь нам нужно просто-напросто разметить публикуемую на сайте информацию особым образом. И, очевидно, что кто-то уже придумал разные словари характеристик объектов и отношений между ними, и, именно, вот эти словари мы будем использовать. Тогда вопрос: а зачем я тратил время на описание RDF? А как вы думаете, что я делал, когда записывал в самом первом теге приведенных ранее примеров такие атрибуты как xmlns:ns="http://family.site.com/#"? Так вот я как раз и ссылался на некоторые онтологии, ведь не могли же появиться из ниоткуда теги и атрибуты ns:Person, ns:hasColor, ns:hasFriend – они были определены некоторой грамматикой, некоторым словарем, некоторой онтологией. Далее я приведу список наиболее известных и уже нашедших практическое применение словарей:
1. FOAF (Friend of a Friend). Эта онтология служит для описания информации о людях, их интересах, связях с другими людьми. Применяется на сайте Живого Журнала и некоторых социальных сетей.
2. Дублинское Ядро (Dublin Core). Это словарь, созданный специалистами в области хранения и каталогизации информации, служит для представления сведений о том, кто разработал некоторый документ, кто его опубликовал, когда …
3. SIOC (Semantically-Interlinked Online Communities). Цель этого словаря – описать сообщения в форумах, чатах, блогах и связать эти сообщений между собой и другими публикациями по сходной тематике.
4. DOAP (Description Of A Project). Этот словарь служит для описания open source программных проектов.
5. WSMO (Web Service Modeling Ontology). С помощь этого словаря веб-сервисы могут публиковать информацию о себе и о том, как вызвать некоторую функцию сервиса. Вспомните пример из прошлой статьи, когда Семантический Агент обращался к сайту магазина торгующего молоком и резервировал для вас товары.
И еще множество грамматик ориентированных на специфические предметные области: страны, товары, географическая информация и т.д.
Теперь очень важный момент: словари не существуют отдельно друг от друга: они смешиваются. Например, вы сделали запись в своем блоге и разметили ее с помощью SIOC, к этой заметке кто-то написал интересный комментарий (идентифицировавшись с помощью openid). Я посетил сайт этого человека, мне понравилось информацию, которую он публикует, и я хочу пойти дальше. Например, найти в каких социальных сетях он участвует, найти список его друзей (возможно, у них тоже есть блоги по интересующей меня теме), здесь мне поможет FOAF. А затем я хочу найти все опубликованные друзьями этого человека статьи определенной тематики (и снова мне поможет SIOC).
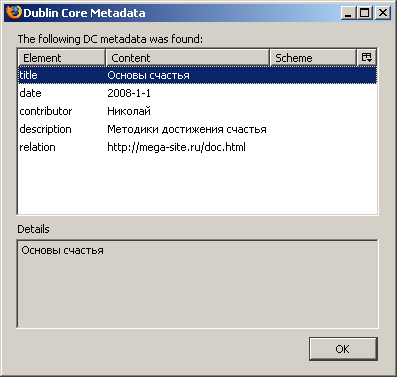
Давайте ближе к практике: рассмотрим пример внедрения в html-код страницы информации об этой публикации с помощью дублинского ядра (Dublin Core). Это спецификация очень простая, плюс, она переведена на русский язык Алексем Бешеновым (http://beshenov.ru/). Спецификация разделена на две части или набора тегов: простой (15 тегов) и дополнительный (плюс три новых тега) В самом начале html-документа вы должны указать, что это не простой html-файл, а содержащий RDF-информацию, за это отвечает тег “head” и его атрибут “profile”.
<head profile="http://dublincore.org/documents/dcq-html/"><link rel="schema.DC" href="http://purl.org/dc/elements/1.1/" /><link rel="schema.DCTERMS" href="http://purl.org/dc/terms/" />
<meta name="DC.date" content="2008-01-01" /><meta name="DCTERMS.audience" content="Заинтересованные в Semantic Web" />
<meta name="DC.contributor" xml:lang="en" content="John Dow”/><meta name="DC.contributor" xml:lang="ru" content="Вася Пупкин”/>
<link rel="DC.relation" href="http://mega-site.ru/doc.html" />
| Элемент | Описание |
| contributor | Участник, внесший вклад в разработку данного документа |
| coverage | Области применения документа: как временные, так и географические. |
| creator | Лицо, ответственное за разработку документа |
| date | Дата разработки или публикации документа |
| description | Описание документа |
| format | Формат документа (например: html, pdf или rtf-файл) |
| identifier | Уникальный идентификатор документа (возможно Интернет адрес или номер в системе ISBN) |
| language | Язык документа |
| publisher | Лицо, выполнившее публикацию документа |
| relation | Документы, связанные с этим файлом |
| rights | Информация о правах владения документом |
| source | Источник, на основании которого шла разработка документа |
| subject | Тема документа в виде ключевых слов, терминов |
| title | Заголовок документа |
| type | Жанр документа |
В следующий раз я продолжу рассказ о технологиях Semantic Web и перейду к FOAF.
| « Семантическая сеть. Часть 1 | Семантическая сеть. Часть 3 » |