| « Узнай больше об проекте wiki2chm | Разработка веб-страниц с помощью google gears. Часть 2 » |
Разработка веб-страниц с помощью google gears. Часть 1
В последний год все более становится все более яркой тенденция сращивать веб-приложения с традиционными “настольными” версиями программ. Конечно, это уже давно не новость. Если углубиться в историю, то первые решения такого рода появились еще во времена первого бума и последующего краха дот-комов. Но именно сейчас, начинает меняться фокус приложения сил. Смотрите: раньше целью декларировалась доставка в “настольную” программу содержимого из internet (в простейшем случае поиск по справке выполнялся не только в файлах на жестком диске компьютера, но в internet). Сейчас мы говорим: а давайте расширим возможности веб-приложения, дадим ему возможность выполняться на машине компьютера без подключения к сети. Дадим возможность хранить часть информации локально, а часть - в сети. Давайте доставим по сети на машину клиента ядро программы (не просто сайт с парой страниц, а сложное приложение, наподобие google docs). Затем пользователь может работать в “сайто-программе”, а на стадии сохранения информации или для получения дополнительной функциональности подключится к сети. Что вы говорите? Слышали это в рекламе пару лет назад? Не ново? Согласен, сейчас мир IT устроен так, что революции произойти не может, части технически продвинутых “гиков” будут мешать консервативно настроенные пользователи (коих большинство). Эти “консерваторы” будут сопротивляться: ведь они совершенно не понимают, зачем им нужно устанавливать у себя на компьютере какие-то непонятные и потенциально опасные плагины, зачем им нужно менять столь привычный internet explorer на новомодный firefox. Людям не нужна “классная” технология сама по себе, им нужны удобные инструменты для работы, такие чтобы ими можно было начать пользоваться без дополнительных затрат времени. К чему я веду этот разговор? К тому, что нужно заниматься популяризацией технических идей, нужно чтобы как можно больше людей занимались разработкой полезных и нужных веб-приложений. Я очень уважаю компании adobe, microsoft, sun. Мне очень нравится те продукты, которые они представили на рынок: air (в девичестве apollo) , silverlight, javafx. Но все дело в том, что разработка с помощью их требует изрядных сил и познаний. Да, продукты получаются качественные (при отсутствии кривизны рук у разработчиков), но и слишком дорогие. Мне нравится политика google: они не создают общие инструменты для веб-разработки, коих на рынке итак уже переизбыток. Они создают сервисы (Google AJAX Feed API, Google AJAX Search API, Google Chart API, Google Checkout API). Затем они предоставляют для всех желающих api, учебную документацию рассказывающую “как программировать на этой штуке”, а потом проект начинает развиваться за счет приложения сил многих миллионов пользователей сети. Неправда, ли хороший лозунг: “заставь на себя работать весь мир”? Об одном из таких сервисов google gears, я хочу сегодня рассказать.На самом деле, я немного лукавлю: Google gears не просто веб-сервис (вроде той классной javascript-библиотеки загружающей вам на сайт список новостей). Google gears нечто большее – это плагин (о ужас, его нужно устанавливать) для вашего браузера. В настоящее время поддерживаются internet explorer, firefox, safari (фанаты opera, вам придется обождать). Впервые я столкнулся с gears весной 2007, когда на странице моей подписки на rss-новости (google reader) появилась функция offline-просмотра новостей. Тогда меня это не впечатлило: как раз таки, рынок rss-ридеров достаточно плотно заселен. Сам я пользуюсь встроенной в opera поддержкой чтения rss-лент и не особенно думаю об ее смене. Тогда я не заметил за лесом деревьев. Вернувшись к этой теме спустя время, я задумался над тем, как реализована эта функциональность и можно ли ее использовать в своих проектах? Оказалось, что использование google gears позволяет строить сайты нового типа, с изменениями и улучшениями не в “рюшечках”, а в методике показа информации.
Предположим, что вы хотите сделать новостной сайт или сайт публикующий статьи и учебные материалы. Естественно, что важен не только сам материал, но и его обсуждение. Часто бывает так, что люди пишут в комментариях более ценные для вас замечания, чем, собственно, текст статьи. Ага, давайте сделаем rss-ленту, в которой будут публиковаться все сделанные комментарии. Нет проблем – на многих продвинутых сайтах и блогах подобная функция есть. Вот только, удобно при чтении этих комментариев (ведь многие из них могут приходить спустя несколько дней или недель) иметь перед глазами исходный текст статьи. Неплохо, чтобы комментарии были бы привязаны к определенным местам в статье, как сноски, неплохо чтобы вы имели возможность добавлять собственные комментарии, видимые не только для всех, но и для определенных групп посетителей или только для самого себя. И тут никак универсальным программами rss-ридерами не обойтись. С другой стороны очень не удобно периодически заходить на сайт, чтобы проверить появились ли новые заметки по интересующей вас теме, загружая каждый раз заново все содержимое статьи (которое, наверняка не поменялось). Почти все, что я описал выше можно сделать с помощью javascript и ajax. Вот только, как быть с хранением данных, тех самых личных заметок, или содержимого статьи? Как быть, если вы начали писать комментарий, но не успели т.к., например, были вынуждены уйти, но хотите придти завтра и продолжить с прерванного места? Где хранить эти данные? В какой-то еще одной программе? Не удобно? Почему так распространены всевозможные сайты-сервисы “быстрых заметок”? Вся беда в том, что в браузере нет “пристойных” средств для хранения пользовательской информации. Я специально отметил слово “пристойных”. Все знают об cookie, небольших кусочках информации, которые сайт может сохранить на машине пользователя, так чтобы при последующем посещении эту информацию взять и использовать. Традиционно cookie используются для хранения небольших данных, например, имя под которым посетитель сайта зарегистрирован. Информация может храниться в течении некоторого времени, несколько дней или месяцев. Вот только назвать cookie “пристойным” хранилищем информации – нет, и еще раз, нет. Попробуйте, например, запустить следующий js-код:
for (var i = 0; i < 1000; i++)
document.cookie = 'var_' + i + '=' + 'value_' + i + ';';
alert (document.cookie);
alert ((document.cookie).length);
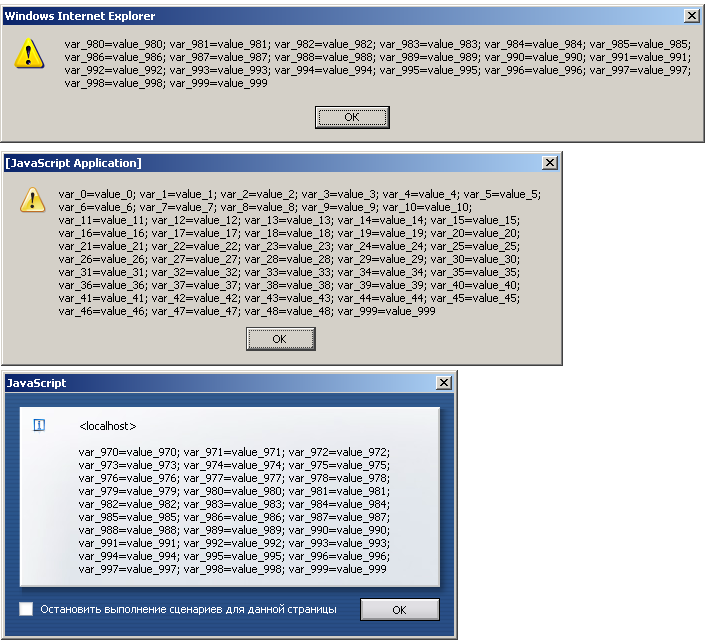
Это очень простой пример: в нем я помещаю внутрь cookie множество переменных с именами “var_0”, “var_1”, … “var_999”, каждой из этих переменных я присваиваю значение “value_0”, “value_1”, …,“value_999”. После окончания цикла я вывожу значение переменной “document.cookie” и длину этой переменной. Все cookie, которые вы сохраните внутри страницы, помещаются внутрь одной служебной переменной с именем “document.cookie”. Эта переменная имеет тип данных “строка” и внутри выглядит примерно так:
fio=vasyan; expires=Mon, 07 Jan 2008 20:51:46 GMT; path=/docs/java/; domain=www.site.com; secure
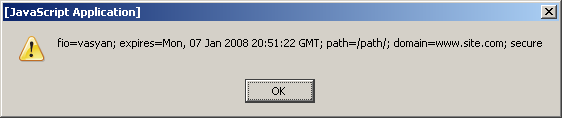
Как видите, в одной строке находятся множество переменных, для каждой из них указывается имя, значение переменной, срок хранения, права доступа (каталог и домен из которого данное значение cookie будет доступно). Затем информация, помещенная внутрь cookie, сохраняется в виде небольших файликов на вашем компьютере. Проблема не в том, что такой формат представления данных не удобен (благо, существует множество пользовательских js-функций упрощающих операции “положить что-нибудь в cookie”, или “изъять”, или “удалить содержимое cookie”). Проблема в том, что если запустить данный пример кода в трех браузерах: internet explorer, firefox, opera –мы получим различные результаты. Так для ie внутри переменной “document.cookie” окажутся только переменные с номерами от 980 по 999, а длина выводимой строки будет равна 378 символов. Как же в этих 378 символах смогла уместиться аж тысяча пар строк, каждая длиной в добрых десятка два символов? Посмотрим, что покажет opera. Вывелись переменные с 970 по 998 - уже лучше - целых 568 символов. Но все равно куда-то пропали девять десятых всех помещенных внутрь cookie переменных. А что покажет firefox? Тут результат еще забавнее: вывелись переменные в интервале от var_0 до var_48, затем пустота и, наконец, одинокая переменная под номером 999. Длина строки “document.cookie” для “лисы” равна целых 830 символов. Увы, но браузер сохраняет не любую информацию, помещенную в cookie, а только ту, которая укладывается в лимит 4 кб. Есть ограничения на количество файлов cookie в рамках одного домена. Так для internet explorer эта цифра составляет 20, для firefox – 50 и для opera – 30. Это еще не все. Для internet explorer суммарный объем всех cookie должен быть не более 4кб, а для остальных браузеров – 4кб. – это ограничение на один файл. Кроме того, в cookie неудобно хранить сложные структуры данных. Например, вы хотите сохранить не просто пару “ключ => строковое значение”, а массив элементов, или объект. В такой ситуации остается только умыть руки.
В настоящий момент очень мало кто хранит сведения собираемые на сайте, именно, внутри cookie. Обычно в cookie помещается некоторое число – код сессии (имя файла, номер записи в БД). Когда открывается веб-страница, то идет обращение к http-серверу с указанием имени страницы, которую вы хотите открыть, плюс, передается содержимое cookie. Затем на сервере на основании номера сессии выполняется поиск в файле или таблице БД реальной информации (той информации, которой много более чем 4кб., той, которая может содержать сложные структуры данных). Естественно, что не всегда следует и не всегда возможно хранить информацию на сервере. Например, при разработке крупных и часто-посещаемых сайтов средства работы с сессиями переписываются фактически с нуля. Особенно ярко такая тенденция появилась с широким внедрением идей web 2.0. Веб-страницы, постоянно обращающиеся с помощью ajax к веб-серверу за информацией, способны свести с ума любую систему поддержки сессий (хранения пользовательской информации) на стороне сервера. В тех редких случаях, когда я был вынужден хранить большие данные на стороне клиента, то приходилось использовать средства flash. Дело в том, что встроенные в flash методики “сохранить немножко информации на стороне клиента” гораздо либеральнее, чем стандартные средства браузера.
Верить, что разработчики браузеров решат пересмотреть методику работы с cookie и добавят в браузеры новые возможности - не стоит. Тем более не стоит верить в то, что они это сделают единообразным образом и в полной мере удовлетворят потребности веб-разработчиков.
Сегодня я обещал рассказать о google gears. Сначала нужно скачать плагин для вашего браузера по следующему адресу: http://gears.google.com/download.html. Там же вы найдете документацию и примеры работающие с google gears. Но прежде чем я перейду к техническим деталям, позвольте мне напомнить в очередной раз: “серебряной пули нет”.
Одной из ключевых возможностей этого плагина (далеко, не единственной) является новая, абсолютно новая, модель хранения пользовательских данных на компьютере. Такого вы еще не видели! Вы знаете, что такое базы данных? Да, это те самые невероятно дорогие (или совершенно бесплатные) штуки, которые могут хранить миллионы единиц информации, мгновенно искать среди их нужную. Еще вы слышали, что для того чтобы научиться работать с базами данных нужны долгие годы. На самом деле существует огромное множество различных баз данных (популярных, конечно, гораздо меньше). Базы данных ориентируются на различные платформы и сегменты потребителей, есть такие СУБД, что запустить их даже на мощном современном ПК – нетривиальная задача. Есть и такие СУБД которые могут быть встроены внутрь вашего мобильника пятилетней давности. Для веб-сайтов традиционно применяют такие СУБД как mysql, postgres. Серьезные предприятия хранят информацию в microsoft sql server, oracle, ibm db2. И есть среди этого списка такая СУБД как sqlite. Это достаточно необычная СУБД, и многие из ее возможностей наверняка отпугнут “зубров программирования”, тем не менее, она завоевывает известность и для поддержки в internet небольших сайтов, и для создания “портфельных приложений”. Под “портфельными приложениями” я понимаю ситуацию, когда программе нужна для работы БД, но при этом предполагается, что приложение будет переноситься на flash-ке или распространяться на CD-диске. Естественно, что требовать установки каких-то драйверов к БД и ее предварительной настройки перед работой – просто глупо, клиенты не оценят. Еще один сегмент рынка, где властвует sqlite – всевозможные встраиваемые приложения. Для работы sqlite достаточно всего 200 кб. памяти. А если и этого вам окажется мало, то благодаря тому, что sqlite – open source, “продвинутые” программисты всегда могут “поработать напильником”. Так что google gears – это всего лишь добавили внутрь браузера небольшую СУБД? Не только. Исторически первым об идее внедрить в браузер хоть не большую, но базу данных заговорили в mozilla, планируя добавить эту функцию в firefox (новые возможности для разработчиков плагинов). Google gears – это не просто sqlite, программисты из google не пошли по пути создания мало кому нужной внутри браузера мини-СУБД, не стали добавлять к sqlite возможности ее “старших” братьев. Они придумали и реализовали другую методику согласования содержимого находящегося в локальной базе данных на машине клиента и данных доступных на сервере. Теперь та картинка с развитой системой комментариев на новостном сайте становится возможным. Подсистема google gears загружает в локальное хранилище неизменяемую информацию на сайте, так что теперь вы можете работать с ней без выхода в Интернет. А когда подключение к сети будет восстановлено, то gears выполнит синхронизацию локальной информации и той, что доступна на сайте (вдруг, за это время появились новые статьи или комментарии).
Условно google gears состоит из трех частей:
1. Локальный сервер, который кэширует нужные для работы приложения ресурсы, такие как javascript, html, картинки. Слово “сервер” в названии может ввести в заблуждение. Но это совсем не означает, что вы можете с его помощью выполнять на стороне клиента php-скрипты.
2. Локальная база данных, построенная на основе sqlite.
3. Подсистема синхронизации, позволяющая выполнять перенос информации между клиентом и сервером.
Я покажу, как работать с gears, начав с простого примера, который не взаимодействует с сервером. Пока попытаемся хранить информацию только локально. В качестве примера будет записная книжка. Веб-страница будет содержать текстовое поле, куда нужно ввести некоторую заметку и кнопку “сохранить”. По нажатию на кнопку в базу будет помещаться введенная строка. Естественно, что при перезагрузке страницы все введенные данные не будут потеряны, а будут отображены чуть ниже формы.
Первое с чего мы начнем – определим установлен ли у нашего клиента google gears. Для этого я подключу к html-файлу приложения js-файл gears_init.js (его можно загрузить по адресу http://code.google.com/apis/gears/resources/gears_init.js). Затем я обращусь к глобальным переменным gears и google. Если этих переменных нет, то на компьютере нет и google gears.
<script src="gears_init.js"></script><script>if (!window.google || !google.gears) {alert ('google gears не установлен'); }else{ alert ('Работаем с gears'); }</script>
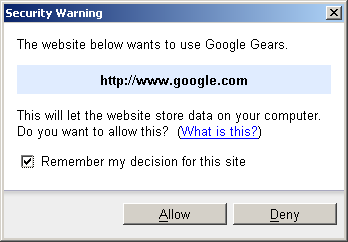
Естественно, что в последующем вы можете просмотреть список “доверенных” сайтов и скорректировать его (меню Settings->Google Gears Settings). После подключения к странице gears следует создать объект-подключение к базе данных. Для этого используйте функцию google.gears.factory.create. Это универсальная функция создающая все объекты, с которыми только работают gears.
db = google.gears.factory.create('beta.database', '1.0');
if (db) {
db.open('notebook');
}
db.execute('CREATE TABLE if not exists notes (id_note integer PRIMARY KEY NOT NULL,
note_title varchar(50) NOT NULL, note_date date, note_text text)');
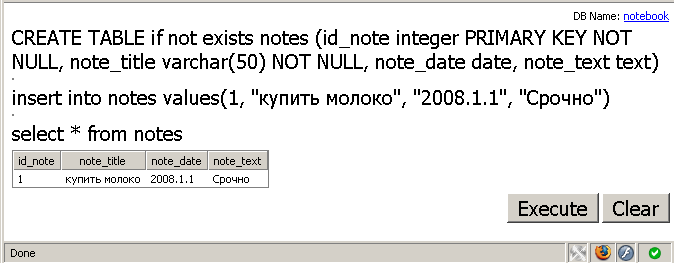
В следующий раз я продолжу рассказ о Google Gears. Нам осталось рассмотреть методы работы с таблицами. Научиться вносить в них записи, удалять и изменять информацию. Рассмотрим методы обмена данным с удаленным веб-сервером.
| « Узнай больше об проекте wiki2chm | Разработка веб-страниц с помощью google gears. Часть 2 » |